- Write a nested-loop flowchart for solving a triangular system. The outer loop is over rows; the inner loop is over columns of the current row.
- Write a function that solves a triangular system. Test your function by sending triangular systems that you can verify easily. (In this version just assume the matrix is non-singular.) You function should satisfy this description:
SolveL(A,b,ax) Argument Explanation ------------------------------------------------------------------------------------ A N × N lower triangular matrix b N × 1 constant vector ax address to place resulting solution x*
Open the code below. It is a shell for this function which you can then fill in code to carry out the algorithm above.
23-SolveL.ox 1: #include
2: 3: SolveL(A,b,ax) { 4: decl n, j, S; 5: ax[0] = constant(.NaN,b); //initialize x* 6: for(n=0;n < rows(A);++n) { 7: // put code here to solve ax[0][n] 8: } 9: } 10: 11: main() { 12: // Put calls to your function to test it 13: 14: } - Once your SolveL() function works, modify it so that it implements an additional feature:
⋮ Returns the determinant of A, |A|. If A has a numerically zero determinant it returns exactly 0 as the determinant and does not complete the solution to x*. - Once your SolveL() code works try eliminating the inner loop by using vector multiplication and subranges of A and ax[0].
- Make a copy of your
SolveL()function, rename itSolveU(), and change the code to solve an upper triangular system. - Write your own
MyInvert(A)function to replace the standardinvert(A)usingdeclu()andsolvelu(). Your function returns the inverse if successful or the integer 0 if the inverse fails. - Modify
MyInvert(A)to not usesolvelu(). Instead, use yourSolveL()andSolveU()coded earlier. - Compute $f^\star$ for two different transitions:
$P_A = \pmatrix{0.8& 0.2\cr
0.3& 0.7}$ and $P_B = p\matrix{ -0.\overline{9}& 0.\overline{0}9 \cr 1 & 1}.$
Use the Markov iterative process and the linear systems approach. For Markov, tart both from $f^0 = \pmatrix{ 0.5 \cr 0.5}.$ Print out how many iterations until convergence. Extra: use the timing functions shown in the
ox-loops.oxcode to time the two solution methods on the two transitions. - Modify
24-fgrad-eps.oxto compute the derivative of $f(x)=\sin(x)$. Look up the analytic derivative if you do not remember it. Compare the numerical results to the analytic value at different values of $x$, including some near the top of $\sin(x)$ and some in between a peak and trough. - Write an Ox function
f(x) which returns $f(x) = x^a$. Here $x$ is a variable sent to the function and $a$ is a parameter which is stored in a global constant. Use thedot exponent
operator.^so that if $x$ is a vector your function will return the vector of values. - Recall that $f^{\,\prime}(x) = ax^{a-1}$. Add a function
fp(x) which returns the analytic derivative of $f(x)$. Set $a=3$ and have your main program call $f(x)$ and $fp(x)$. Print out the returned values for $x=2$ and confirm the values are correct. - Write a function to compute the general Cobb-Douglas form in (CobbDougOX) with these features:
- Use
returnto return the resulting value of the function.- Use a static global constant to store $\alpha$.
- Use
.^andprodc()to implement the symbolic operators in (CobbDougOX)- Your function can be written with one statement inside its curly brackets.
- Use
- Write a program to compute the numerical first and second derivatives of $$f(x_0,x_1) = \log\left({e^{x_0}\over 1+e^{x_0}}\right)+\log\left({1\over 1+e^{x_1}}\right)\nonumber$$
- Looking for the Next Best Thing♭Warren Zevon 1984 Part 2. Carry out the bracket-and-bisect algorithm on the mystery function called by
mystery1d_main.ox. - Modify
26-poly-roots.oxto find all the roots of the polynomial of $g(x) = 1+x-2x^2-x^3+0.5x^4-0.1x^5$. Then code a function in the form needed bySolveNLE()that usespolyeval()to evaluate the polynomial. CallSolveNLE()and see if it converges to one of the real roots and whether it converges to different roots based on initial values or choice of Newton-Raphson or Broyden. After experimenting, write a program that startsSolveNLE()at different values that converge to different roots. - Consider a 2x2 system of the form: $g(x) = \l(\matrix{g_0(x)\cr g_1(x)}\r)$
$$\eqalign{
g_0(x) &= \log(x_0) - x_1^2\cr
g_1(x) &= \sin(x_1) - \cos(x_0)\cr
}\nonumber$$
- Write a function called
sys_internal(x)that expects a 2x1 vector and returns $g(x).$ Test your code by sending the vector $\l(\matrix{1\cr 1}\r)$ tosys_internal()and printing the output. You should get g():-1.0000 0.30117 - Write a new function named
sys()that follows the format required bySolveNLEand is a "wrapper" around your simplersys_internal()function:sys(ag,x)
sys_internal()and returns 1. Verify yoursyscomputes the correct value for<1;1>and returns 1. - Use
SolveNLEto solve for a root of the system. Check the convergence code. Try different starting values to see if it finds more than one root. Start at an undefined value (say $x_0=-1$) and see what happens.
- Write a function called
- On the $x_0$-$x_1$ plane the intersection of a line and a circle is the solution of a non-linear system. The particular system is of the form
$$g(x) = \left(\matrix{g_0 \cr g_1 }\right) = \left(\matrix{ x_0+x_1 - v \cr x^2_0 + x^2_1 - 9 \cr}\right).$$
The parameter $v$ should be stored as global variable. Set it to $v=3.$ You should be able to see there are two solutions at $(0,3)$ and $(3,0)$. Further, the analytic Jacobian is easily computed as
$$Jg(x) =\left(\matrix{ 1 & 1 \cr 2x_0 & 2x_1 \cr}\right)$$
- Solve this problem numerically using
SolveNLE()and Broyden's method following examples already done. Start with use of a numerical Jacobian. - Write your main code to start at values near the two solutions and see if they converge to the closest one.
- Code the analytic Jacobian and run Newton-Raphson with it.
- If you increase $v$ from 3 the two roots move closer together until eventually they meet when the line is tangent to the circle. If you go past that point there is no solution. Experiment with changing $v$ to find the tangency and see what happens when no solution exists. Here is a loop that would make it easier to do this ... insert in your main code and adjust $v$. You might also confirm analytically the value of $v$ that results in a unique root and enter it to confirm.
while (TRUE) { scan("Enter v ","%g",&v); // reset your starting/ vector here SolveNLE( ... ); }
- Solve this problem numerically using
- Go through your intermediate economic theory notes/textbooks. Identify all the theoretical components that are actually optimization problems. Classify them according to the following:
- one dimensional vs. multi-dimensional
- constrained vs. unconstrained
- Continuous vs. discontinuous
- local vs. global
- Looking for the Next Best Thing Part 1. Open the Ox program
mystery1d_main.oxand run it. You will be prompted for an $x$ value. A mystery function will be evaluated at $x$ and the value will be returned. Try to find the optimum $x^\star$ and the optimal value $f(x^\star)$. - Looking for the Next Best Thing♭Warren Zevon 1984 Part 2. Carry out the bracket-and-bisect algorithm on the mystery function called by
mystery1d_main.ox. - Apply both steepest ascent and Newton's method to maximize the (a) Rosenbrock function and (b) a simple quadratic function in two variables. Compare the rates of convergence.
- Consider the function $$g(x_0,x_1) = -x_0^2 + \alpha x_0 x_1 - x_1^2.\nonumber$$ We already have seen how this function behaves when the parameter $\alpha$ is set to 1. Derive the 2×2 Hessian and show that the function is strictly concave as long as $\alpha<2$, but for $\alpha \ge 2$ the function now longer has a maximum.
- Save
27-maxnewton.oxto a new file. Setbeta=0and modify it so that a new parameteralpha=0.5). Now set $\alpha = 1.999$ and then $\alpha = 2.0001$. Run the program to see how this affects the performance of Newton's method. - Modify the code below to start BFGS and Newton at the same point to maximize it. Compare the number of function evaluations required to find the maximum.
28-rosenbrock.ox 1: #include "oxstd.h" 2: #import "maximize" 3: 4: decl fevcnt; 5: 6: rb(x,aF,aS,aH) { 7: aF[0] = -(1-x[0])^2 - 100*(x[1]-x[0]^2)^2; 8: if (!isint(aS)) Num1Derivative(rb,x,aS); 9: if (!isint(aH)) aH[0] = -unit(2); 10: ++fevcnt; 11: return 1; 12: } 13: 14: main() { 15: decl z = <1.5;-1.5>,frb,ccode; 16: rb(z,&frb,0,0); 17: MaxControl(-1,1); 18: fevcnt = 0; 19: // ccode=MaxNewton(rb,&z,&frb,0,1); //MaxBFGS Newton 20: ccode=MaxBFGS(rb,&z,&frb,0,1); //MaxBFGS Newton 21: println("x*=",z,"f(x*)=",frb,"/n convergence = ",ccode 22: ," #of eval: ",fevcnt); 23: } 24:- The function
$$L = \sum_{i=0}^{N-1} \ln\left( {e^{y_i x_i\beta}\over 1+e^{x_i\beta}} \right)$$ is the likelihood function for a simple (binary) logit model. This model explains which of two discrete outcomes happens ($y=0$ or $y=1$) using the row vector $x_i$ as explanatory variables. For example, explaining who goes to university or not depending gender, high school grades, parents' education. The columns of $x_i$ correspond to the variables like gender. The multinomial logit generalizes the simple or binary logit so that $y$ takes on $J$ different values instead $J=2$ values. The idea of a mlogit is that each option $j$ has its own "utility." The utility depends on the chooser ($i$) and the option ($j$). It also combines deterministic and random components so that there is probability of $j$ being optimal for chooser $i$. So let
$$v_{ij} = x_i \beta_j$$
be the deterministic component and $\epsilon_{ij}$ be the random component, so that utility is:
$$u_{ij} = v_{ij} + \epsilon_{ij}.$$
We observe $i$ choosing the option that maximizes utility their utility:
$$j^\star_i = \arg\max_{j\in 0,1,\dots,J-1}\ u_{ij}.$$
When the residual $\epsilon_{ij}$ follows a particular distribution (the Extreme Value distribution) then we get a specific form for the probability that $j^\star_i=y_i$ (where $y_i$ is the observed choice):
$$Prob( j^\star_i =y_i | x_i, \beta_0,\dots,\beta_{J-1}) = { e^{v_{i\,y_i}} \over \sum_{j=0}^{J-1} e^{v_{i\,j}}}.$$
Notice that this uses the discrete outcome $y_i$ as an index for the correct $v_{ij}$ to include in the numerator, and this in turn depends on $\beta_j.$
We can get back to the simple logit by setting J=2 and $\beta_0 = \overrightarrow{0}.$ That is option $0$ has beta vector of 0s, which means $e^{v_{i 0}} = e^{x_i\beta_0} = e^0 = 1.$ And now that function we've been working with all along becomes a special case of the multinomial logit log-likelihood function: $$L^J = \sum_{i=0}^{N-1} \ln \left( { e^{v_{i\,y_i}} \over \sum_{j=0}^{J-1} e^{v_{i\,j}} }\right),\qquad\hbox{and } v_{ij} \equiv x_i\beta_j.$$ Note that $L^J$ is shorthand. A more accurate definition would be $L^J(\beta_1,\dots,\beta_{J-1}; y, X).$ That is, $y$ and $X$ are taken as given. The vectors of coefficients are variable in order to maximize $L^J.$
In the simple logit we could maximize this function using Ox's
MaxBFGS()by sending a singlebetavector as the parameters to maximize over. In the multinomial model we want to maximize over 2 or more vectors, butMaxBFGS()like almost all optimizers takes only a column vector as the argument to maximize over. Let's define $\theta$ as that vector and think of it containing the "concatenation" of the $\beta_j$'s: $$\theta \equiv \pmatrix{\beta_1\cr\beta_2\cr\vdots\cr\beta_{J-1}}$$ Note that we don't include $\beta_0$ because it is fixed at 0 andMaxBFGS()should not change its values. A function written to compute $L^J$ would "unpack" $\theta$ into a matrix: $$\theta_{(J-1)K\times 1} \qquad \Rightarrow \qquad B_{K\times J} = \pmatrix{ \overrightarrow{0} & \beta_1 & \beta_2 & \cdots & \beta_{J-1}}.$$ Now notice that $XB$ will contain a $N\times J$ matrix consisting of all the values $x_i\beta_j$ for all $i$ and all $j$. So computing $v_{ij}$ and ultimately $L^J$ can be done with vector functions (or with loops over $j$ or both $i$ and $j$). The code and data file in themlogitfolder is designed to build a function to compute $L^J$ and finding the maximizing coefficients using one of theMax????()algorithms. The data come from the example used in Stata to illustrate its mlogit command. The data and estimates are summarized with these screen captures: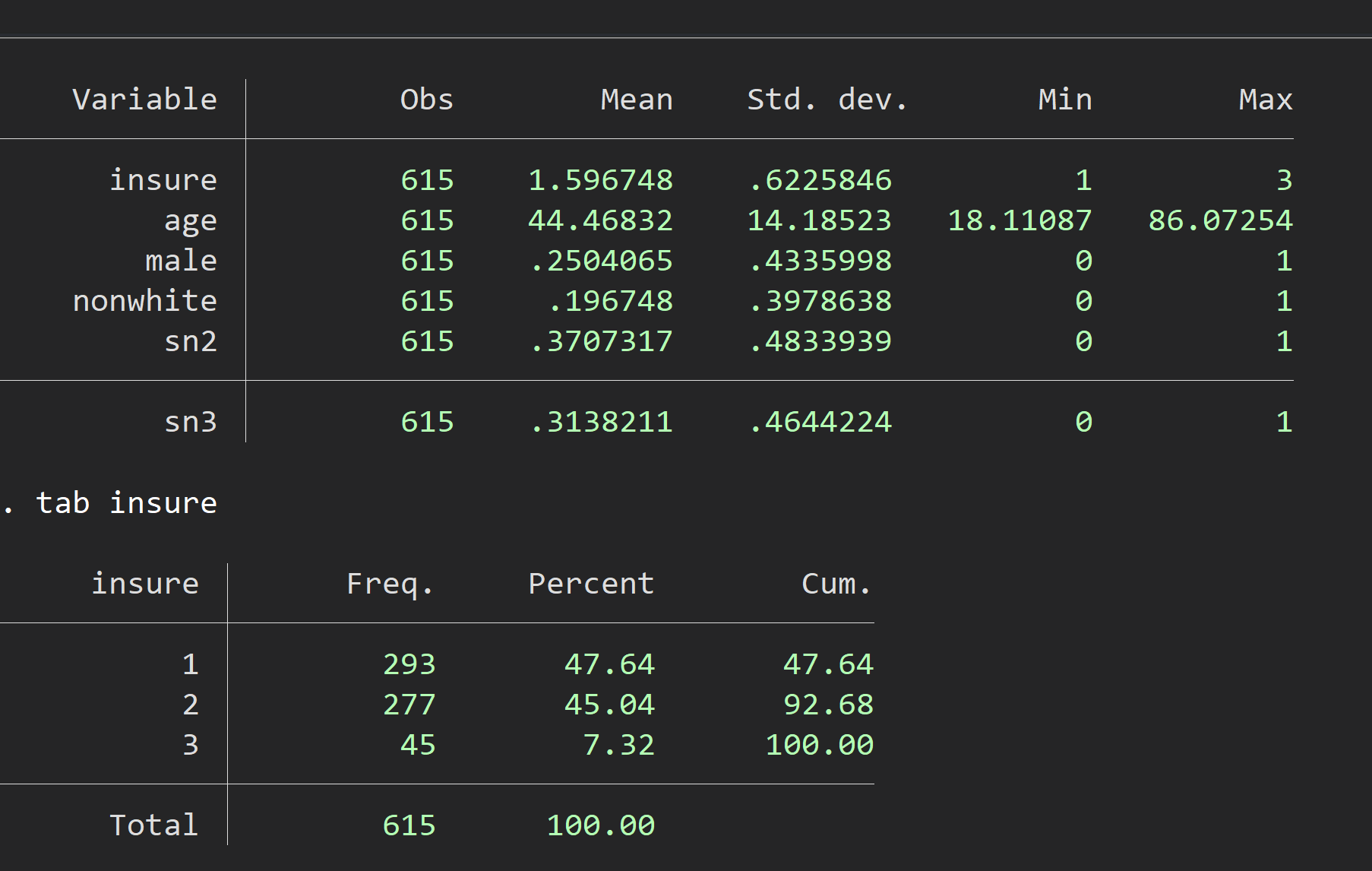
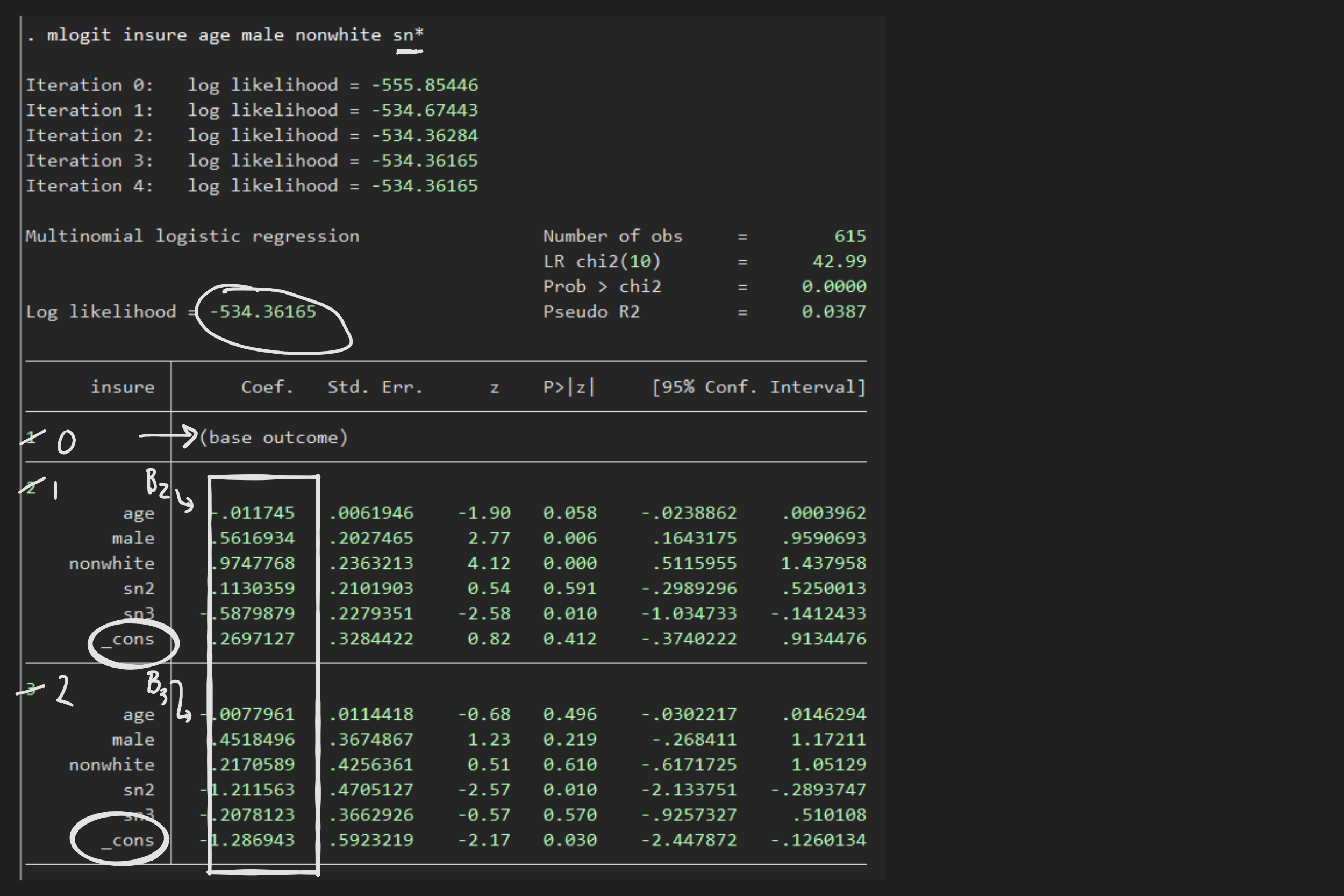
Add code to the files in the folder to:
- Complete coding of LJ
- Create a starting theta vector
- Maximize LJ (use algorithm of your choice)
- Print out results to compare with Stata output
- EXTRA:
- copy over stata_logit_data.dta from the logit folder
- use of loaddemo to load the simple logit data data
- Reset K and J (*NOTE: do not decrement y since it is already 0/1)
- Verify LJ() to provides same results as simple logit
- Simulate the distribution of different things computed from sample data (also know as statistics). Let $X$ follow the $\chi^2_3$ distribution (which is the "chi-squared" distribution with 3 degrees of freedom). See its wikipedia page to discover the mean of this distribution and an explanation. Note:
ranchi()is in Ox'soxprobpackage. Remember that theran?()functions in Ox will return a matrix. So you can draw a $N\times R$ matrix. Each column of that matrix is a sample (each row is observation $i$). Then just compute the statistics for each column. Graph denisities or histograms for samples of size $N=10$, $N=30$ and $N=200.$ In each case, do $R=1000$ replications for each sample size. This takes only a few lines of Ox code.- Simulate $Y_N$ in \eqref{YN} which is the scaled deviation from the population mean. Remember you can use built-in functions and operators to compute the mean of each column of a matrix. Here is the Ox graphing function that will do that if
Ycontains a $1\times R$ row matrix:#includeThe last 3 1's are optional but should make the graph look the way you want ("Graphic Reference" describes the Ox drawing routines).// Draw simulated sample // Compute values of YN in Y DrawDensity(0, Y, "$Y_N$", 1, 1,1); SaveDrawWindow("YN.pdf"); - Not everything we do with sample data follows a normal distribution in large samples even with IID sampling. One example is what are called extreme statistics (whereas the mean is a central statistic). For example, for a sample of $X_i$ of size $N$ define as the largest value in the sample: $X^{max}_N \equiv \max_i\ X_i$ Using the same simulated sample of $\chi^2_3$, graph $X^{max}_N$ and note whether it "looks normal" for large $N$
- Simulate $Y_N$ in \eqref{YN} which is the scaled deviation from the population mean. Remember you can use built-in functions and operators to compute the mean of each column of a matrix. Here is the Ox graphing function that will do that if
- When replicating Stata's multinomial logit output the main equations were:
$$v_{ij} = x_i \beta_j$$
be the deterministic component and $\epsilon_{ij}$ be the ran
$$u_{ij} = v_{ij} + \epsilon_{ij}.$$
We observe $i$ choosing the option that maximizes utility the
$$j^\star_i = \arg\max_{j\in 0,1,\dots,J-1}\ u_{ij}.$$
We took as given that the probability $y_i$ equals to the optimal choice was:
$$Prob(y_i) = { e^{v_{y_i}} \over \sum_j e^{v_j}}.$$
That is true only if the error terms $\epsilon_{ij}$ follow the Type I Extreme Value Distribution (also known as the Gumbel Distribution). Look up its wikipedia page. To draw a N x J matrix use
ranextremevalue(N,J,0,1).- Use the
loaddemo()code to read in the $X$ matrix from the Stata sample. Instead of using the 3 outcome $y$ vector from the data, simulated new $y$ vectors multiple times using Monte Carlo. To do this, you need to have the "true" or population parameter vector, often denoted with a "0," so here $\theta_0.$ Set $\theta_0$ equal to the MLE estimates from the actual data: $\theta_0 = \hat\theta^{mle}.$ Write a function to simulate a sample of $y$ using the same $X$ matrix and $\theta_0.$ THat is compute the simulated $u_{ij}$ and compute $j^\star_i.$ That means you have to store the index of the element in a row or column vector that holds the max (in this case the choice with the highest utility for observation $j$). Ox has amaxcindex()function to do this (or use loops). Note it does not provide amaxrindex()so you may have to transpose your matrix to use it. - For a simulated $y$ vector re-estimate the coefficients using MaxBFGS() as in the previous assignment. Then put this code into a loop to estimate from $R$ simulated samples.
- You can put all the simulated results in a matrix that is $2K \times R.$ Each column is a simulated MLE vector. Compute the distribution of the estimates and compare them to $\theta_0$. (The
moments()function is a good option for this.)
- Use the