Serial vs. Parallel
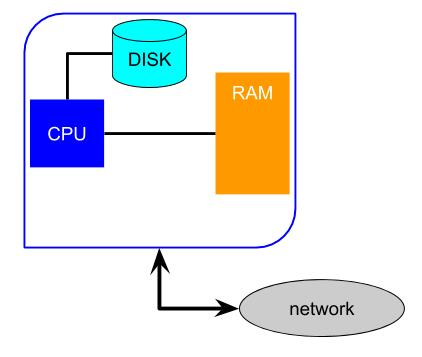
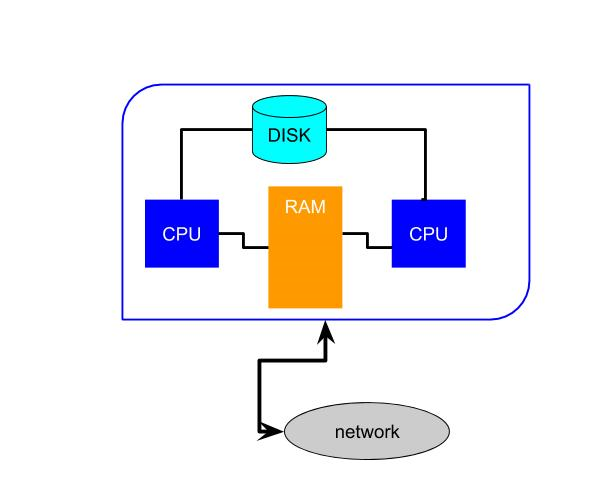
The CPU in Tim, our basic computer introduced earlier, executes commands stored in RAM one at a time. This CPU follows serial execution. The apparent ability to do more than one thing at once is due to a timesharing operating system and the speed of the instruction cycle compared to the slowness of human perception. However, most computers and devices today have more than one processor and can perform true parallel execution. There are well-established ways to get separate CPUs to coordinate. When a computer has, say, a quad-core CPU it means four different (usually identical) processors are executing instructions at once. The operating system can manage which programs run on which core. For example, your web browser might be running on core 1 while you watch a movie shown to you by core 3. This type of parallel execution is unimportant for our purposes, because a program would execute in serial on a single core.Exhibit 26. Single and Double Core Computers with Shared Memory
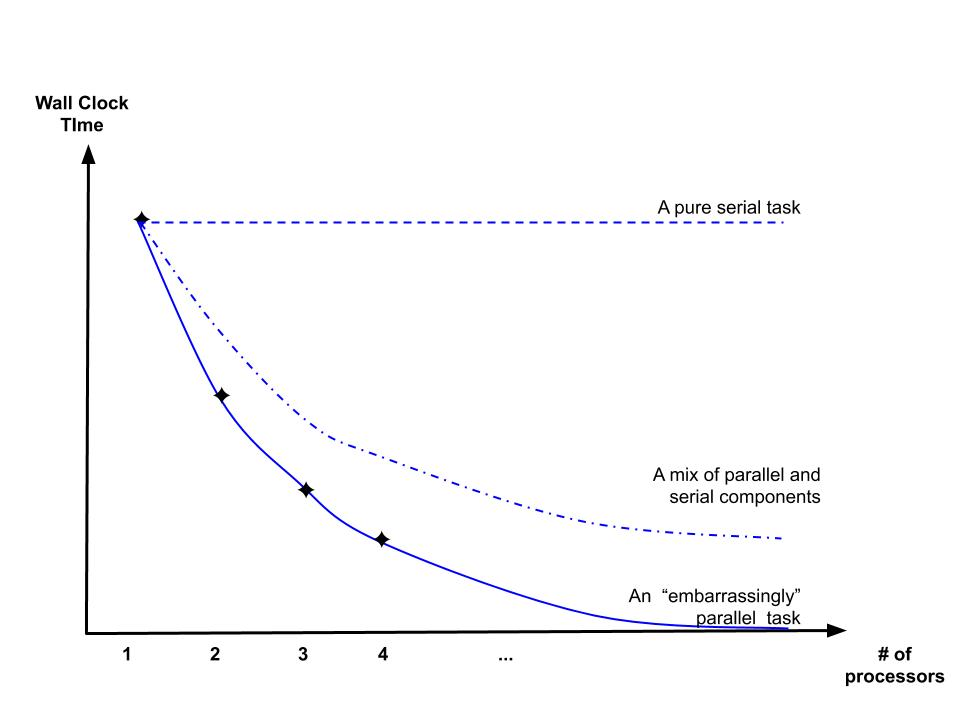
WallClock time can be a challenge because some algorithms and some operations do not lend themselves to parallel execution. That is, parallel execution does not reduce the total number of instructions required for an algorithm to finish. Instead, parallel execution usually results in more instructions to get the job done both to coordinate the multiple nodes and because some instructions may be redundant.
In the worst case, a program runs on two processors at once and simply carries out the algorithm twice. In this case the total number of instructions is doubled and the WallClock time is identical.
In the best case each processor carries out half of the original instructions so the total number is the same but the WallClock time is cut in half. In practice, most algorithms used in economics will fall somewhere between those two extremes in terms of gains from parallel execution. Some parts of an algorithm are easy to run in parallel and some are not. This makes parallel execution somewhat difficult to understand and to implement on ones own.
Exhibit 27. Benefits of Parallel Execution Depend on the Task
Low-Level Parallel Execution: Multi-Threading
One way to distinguish types of parallel execution is between shared memory and distributed memory processing. With shared memory your program is running on two or more processors that access the same memory cells. So if one processor stores $x$ is a memory cell the other processor can access that memory cell directly while it executes. On the other hand, with distributed memory each processor has its own cell for $x$ and cannot access the other memory cells directly. Multi-threading is an important way in which shared memory parallel execution is implemented. The idea is not difficult to understand, but the hardware and software support required to make it work is complex, for the same reason that too many cooks spoil the broth. Multi-threading means that your program will run in serial mode on a single processor until it reaches a point where the algorithm can exploit parallel execution. The program then splits into two or more threads, each executing the same segment of code from your program but for different parts of the shared memory. Once that segment has been completed by all the threads they terminate and return back to a single thread working in serial. Multi-threading is low-level and must be handled by the compiler. Ox version 7.0 Professional is compiled with a multi-thread aware C compiler. So you can tell it to use some or all of your processors. The free Console version cannot multi-thread your program.Exhibit 28. Multi-threading a Vector Operation
float x[200], sum; ===> CPU1 CPU2
... -working- -idle-
-split-
sum = 0.0; sum1=0.0 sum2 = 0.0
for (i=0; i<200; ++i) for (i=0; i<99; ++i) for (i=100; i<200; ++i)
sum = sum + x[i]; sum1 = sum1 + x[i]; sum2 = sum2 + x[i];
-rejoin-
sum = sum1+sum2; -idle-
z = loadmat("z-data");
x = zeros(rows(z),1);
for (i=1; i<200; ++i) {
x[i]= 0.5*x[i-1]+z[i];
}
x[2] depends on x[1]. The Ox compiler cannot know what that value is because it depends on z[1], and that is determined at run time. So this loop includes a dependency and cannot be multi-threaded.
Distributed Memory
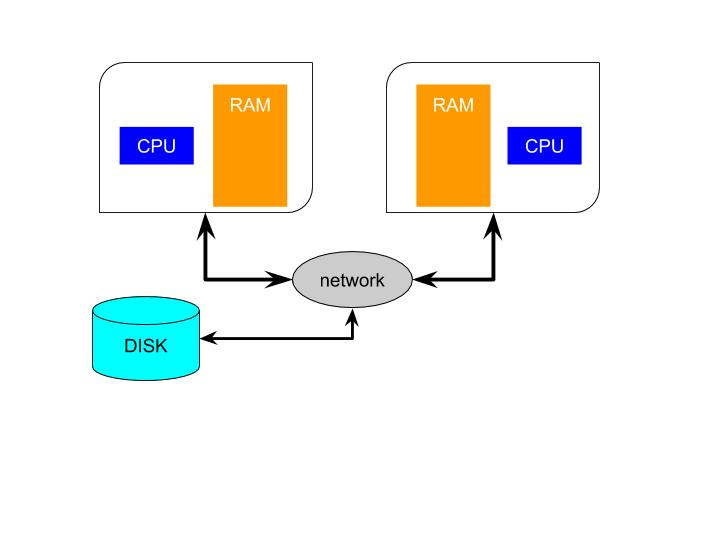
Distributed memory parallel execution is typically less complex to implement because it does not involve a single set of instructions splitting into separate threads and then rejoining again. In fact, it is possible to implement distributed memory parallelism without any special tools as long as the processors can communicate somehow. But typically distributed memory parallelism requires more intervention from the programmer. The compiler cannot coordinate the actions by itself. High Level Parallelism coordinates the activities of independent processors without shared memory. To achieve this efficiently an environment must be created to allow a user's program running on one CPU to communicate to another copy running on another CPU. This is the MPI, the message passing interface. The MPI creates a parallel environment that a single program can run multiple instances of.Exhibit 29. Distributed Memory With and Without MPI
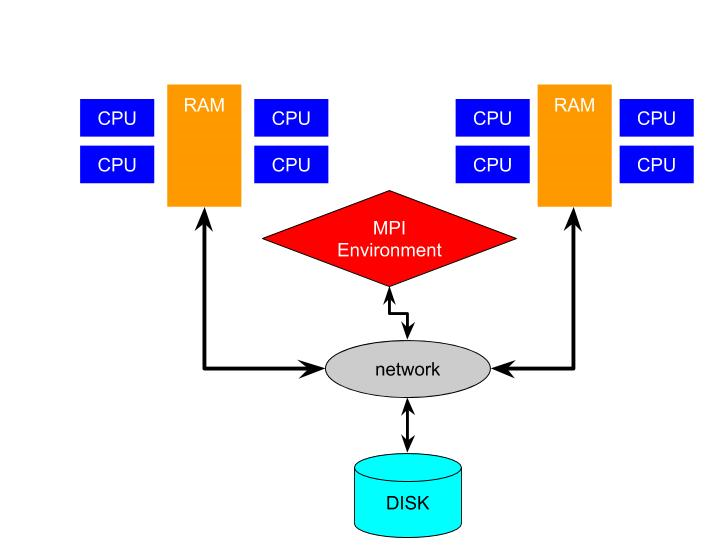
A FAQ introduction to MPI
- What is MPI? MPI stands for Message Passing Interface. It is a standard for coordinating actions between processors independently running multiple instances of the same program. The programs running across processors are called nodes.
- How is this coordination achieved? The different copies of the program are coordinated by sending messages between them as the code executes. Messages are required because as different instances of the same program executes on different nodes the programmer wants them to execute different calculations (otherwise there would be no benefit to running in parallel). The instances are never synchronized so messages allow them to carry out different tasks and to be in different places in the same code in order to perform a single objective.
- What is a message, and how is it transmitted? A message is some data (such as a vector of numbers) and an integer code for what kind of message it is. This code is called the message tag. MPI supports very sophisticated messaging, but the basic features are often all that is required. The computer system(s) that are running the program must maintain the MPI environment. The programmer includes calls to procedures (functions) that access the MPI environment.
- What is the MPI library? The MPI library is the set of procedures (functions) to be called from a program in C, FORTRAN or other languages to use the MPI environment. The programmer only needs to understand and call routines in the MPI library within their program to send and receive messages while the program runs on multiple nodes. The MPI environment handles all the details of information passing for the programmer.
- Are messages like email? Messages sent between nodes are similar to email messages. The environment ensures that messages are delivered to the inbox of the node. Unlike email, the program must process messages one at a time in the order they arrive.
- How are messages sent and received between instances of the program? The programmer must insert calls to the MPI library of routines in their program to pass messages.
- How does my program know about the MPI environment.? If the program is started within the MPI environment then it can and must call
- What are the Two Bare Essential Pieces of Information the Program Gets from
MPI_Init() - 1. N, the number of different processes that are running the program and communicating through MPI. These processors are called nodes, so N represents the number of nodes. If N=1 then the program is running in serial even though the MPI environment is accessed.
- 2. ID, my id or my rank. The ID/rank of each of the nodes take on the integer values 0,…,N-1. Usually the user has no control over which physical CPU is assigned to each
ID. The MPI environment assigns the IDs arbitrarily. - How do N and ID allow for parallel execution of the same program running on separate CPUs with separate (distributed) RAM? Once each copy of the program knows its ID it can specialize to do only some of the required computation. The other computation will be done by other copies with different IDs. In many programs, one ID takes on a special role to coordinate the actions of the other copies of the program. Since IDs start at 0, it is typical for ID=0 to play this role.
- Are there general ways to think about parallel programming using MPI? Yes, there are two
- Client-Server Paradigm
- Peer-to-Peer Paradigm
MPI_Init() to get information about the environment. The MPI environment tells the user's program two pieces of information that are required to coordinate actions.
paradigmsfor organizing use of MPI:
Client/Server Using MPI.
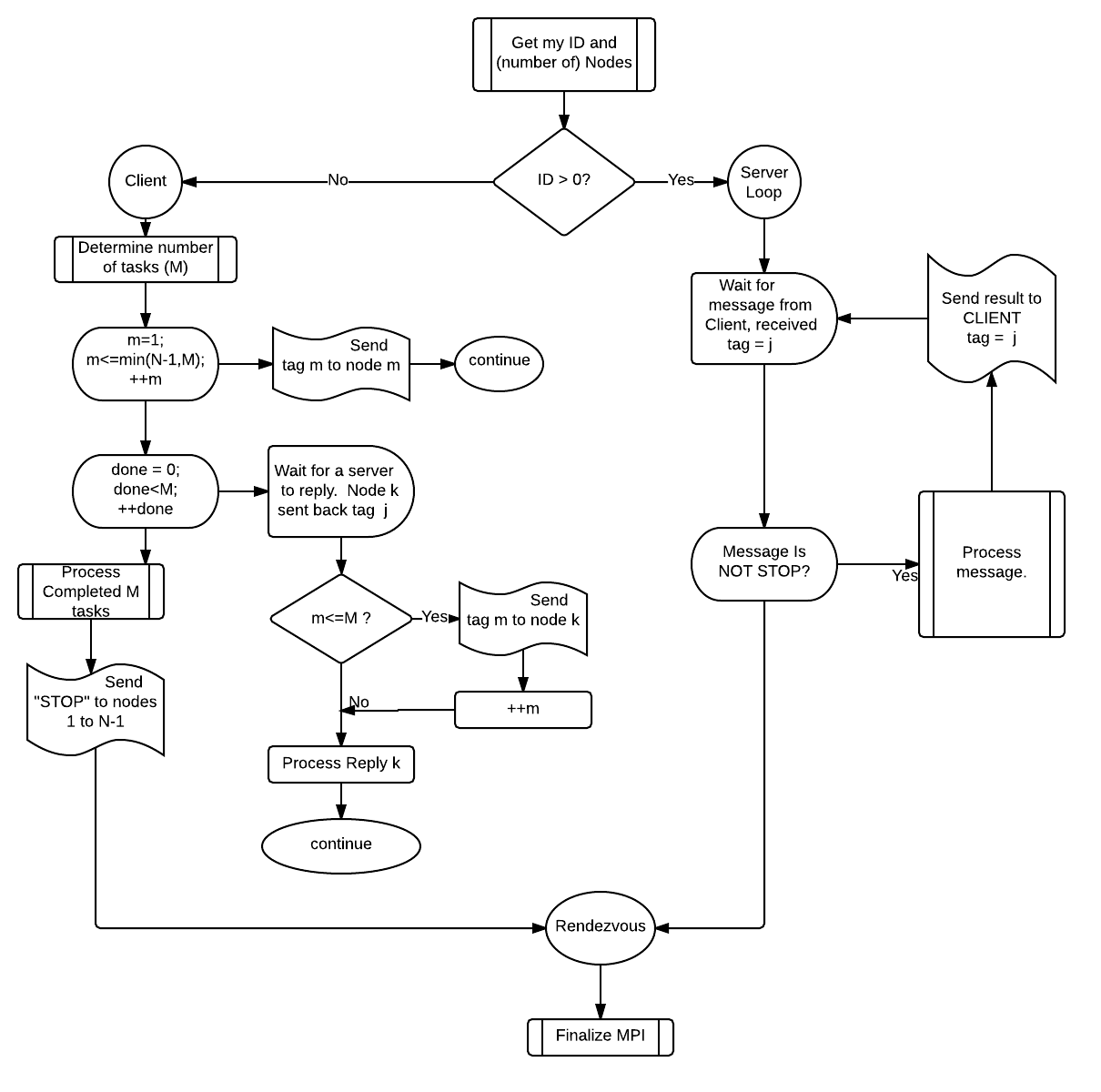
This client/server paradigm involves point-to-point communication, which means one processor sends a message to another. It can be highly flexible (dynamic), thus efficient if the sub-tasks or hardware is heterogeneous. But it requires extensive programming and the use of tags to specify tasks. A Client-Server approach is based on one node (the client) coordinating the actions of the other nodes (the servers). The single program running on the nodes splits into two separate segments of code. The client executes code and calls the server to carry out tasks that can be done simultaneously. The servers execute code that waits for the client to send a task.The Client-Server model relies on node-to-node communication: the client sends a message to a server which later sends a reply back. The servers typically do not communicate with each other. MPI has features that allow the program to keep track of what messages are being sent or received as well as who sent the message and who is supposed to receive it.
Algorithm 1. A Client Server Program
- A single program is started on multiple "nodes" (separate memory).
- Each copy calls
MPI_Init()and gets its ID and how many nodes there are, N. - One node (ID=0) becomes the client; all others nodes become servers.
- The program then splits. The client executes client tasks and servers execute server tasks. Since the copies of the programs are communicating from different points within the same program, the messages must include information about the context.
- This is handled by "tagging" each message with an integer code. The user's program must send and receive the tags.
- Each Servers waits for a task to do and input from the client; it sends results back with the same tag and waits for the next instruction.
- The Client sends tasks and input to servers, waits for output, and uses it. It then repeats this process as the algorithm progresses.
- The Client decides the job is complete; it sends a STOP message (or a STOP tag) to all servers.
- All copies of the program end.
Exhibit 30. Flowchart for (most) Client-Server Programs
Peer-to-Peer Paradigm
In Peer-to-Peer mode all the instances of the program are at the same line of code when messages get sent and received. Peer execution relies on group communication that is coordinated by the MPI environment. That is, instead of messages going from one node to another much of the communication goes between all the nodes at the same time. A node (again usually ID=0) will often play a special role before or after messages are sent. That is, they may process the results shared by all the peers and the broadcast the result to every node. The Group Communication paradigm involves all processors doing the same thing. Coding is simpler that client/server but is less flexible than the Client-Server approach. In Peer-to-Peer mode all the instances of the program are at the same line of code when messages get sent and received.Algorithm 2. Peer-to-Peer Program
- A single program is started on multiple "nodes" (with separate memory).
- Each copy gets its ID and how many nodes there are, N.
- ID=0 is first among peers (less differentiated than client/server)
- Peers work on their part of the job and then share results (broadcast, gather, reduce). No tags are needed because all peers are at the same line of code in the original program when communications occur.
- Stopping point is reached and all end.