Calculus explains instantaneous smooth change. It relies on the notion of a limit: evaluating an expression as a quantity gets closer and closer to some value but never takes on the value exactly.
In the case of derivatives, the expression is a ratio (the secant of a function):
$${f(x+h)-f(x)\over h}\tag{secant}$$
and the limit is as the denominator, $h$, goes to zero At exactly $h=0$ change the ratio is undefined, but the limit can still be well-defined because the ratio is never evaluated at $0$ exactly. In the case of integrals:
the limit expression is the sum of areas of rectangles (or trapezoids) as the base of the shapes goes to 0 length. At exactly zero each area equals zero, but in the limit the sum of the areas is the area under the curve.
Numerical calculus translates these concepts to computation using floating point reals (FPRs). It should seem a bit difficult to translate into digital computation. As we have seen in the chapter on digital arithmetic, a floating point real cannot represent values arbitrarily close to 0 or any other given real number. There is a smallest positive FPR that is not zero, which is not true in the (standard) symbolic real number system, $\Re$. Further, computer arithmetic, such as taking a ratio, cannot produce reliable results anywhere close to the value of smallest positive FPR. Instead, machine $\epsilon_m$ defined earlier, is how accurate floating point arithmetic is near 1.0. With 64 bit FPRS $\epsilon_m$ is about $10^{-16}$.
This means that numerical calculus has two layers of approximation related to symbolic calculus. First, floating point numbers are only an approximation to real numbers; and, second, limits can only be approximated by finite differences. In the case of digital algebra covered in the last chapter, the concept of instantaneous change and approaching a limit are not necessary.
Eventually we will consider functions of several variables (or equivalently, functions of a vector of real numbers). And we will consider functions that produce more than one number (vector-valued functions). For now, consider generalizations of the example above that still are conceptually simple functions of single values. Software functions can both receive and send more than one argument. And since an argument to an Ox function might be an oxarray, even one argument might actually specify many values to be used as input to the function. Further, as discussed earlier, an Ox function that codes $f(x)$ could rely on global variables for input data.
Computed Functions and Analytic Derivatives
Given a symbolic function $f(x)$ we can approximate it digitally with a software function, f(x) or in the form sometimes requested by Ox, f(x,av). In this case, the value of the function is returned to the address av and the function itself returns TRUE if $f(x)$ is defined and FALSE otherwise. To understand a digital approach to the derivative of $f(x)$, first recall the definition. The derivative of a real-valued function at a point $x$ is the slope of the function's tangent line. In turn, the tangent is the limit of the secant as the step size $h$ goes to 0.
$$f^{\,\prime}(x)\ \equiv\ {df(x)\over dx}\ \equiv\ \lim_{h\to 0}\ {f(x+h)-f(x)\over h}.\tag{AD}\label{AD}$$
In many cases an analytic form of the limit is known. For example, if $f(x) = x^n$, then $f^{\,\prime}(x) = n x^{n-1}$, for $n \ne 0$. This is an example of an analytic derivative. Note that the derivative is itself a function of $x$. Since $f^{\,\prime}(x)$ is also a function it can be a different sequence of instructions. If $f(x) = x^2$ then $f^{\,\prime}(x) = 2x$ and we call $f^{\,\prime} = 2x$ its analytic derivative.
Symbolic math often deals with functions that have no analytic expression. That is, $f(x)$ is defined implicitly. Since a computer captures a function as a sequence of instructions, a function that is not analytic can still be computable. We can compute derivatives of a computable function, using numeric derivatives.
To carry out the $\lim$ operation in (AD) we might store $h$ as a floating-point real (FPR) in, say, 64 bits. Recall that a $h$ less than "machine precision" is not reliably distinguished from 0. From then on, $h \doteq 0$ and the ratio in (AD) is .NaN. In other words, it is possible to fully mimic the concept of a limit using floating point numbers.
This might suggest that the best approximation to $f^{\,\prime}(x)$ would be to stop at machine precision:
The numerator is approximately 0 and very inaccurate. Then (MinSEC) divides 0 or something close to 0 by something also almost 0, which does not sound good. The technical term for the result of (MinSEC) is junk.
What is needed is a finite difference (or secant) approximation to the tangent in which $h$ is big enough to have plenty of bits available to reduce round-off errors but not so big that the curvature of $f(x)$ dominates.
Numeric Derivatives
A straightforward translation of $f^{\,\prime}$ leads to a finite numerical approximation of:
$$f^{\,\prime}_{FD}(x) = {f(x+h)-f(x) \over h} \approx f^{\,\prime}(x).\tag{FD}\label{FD}$$
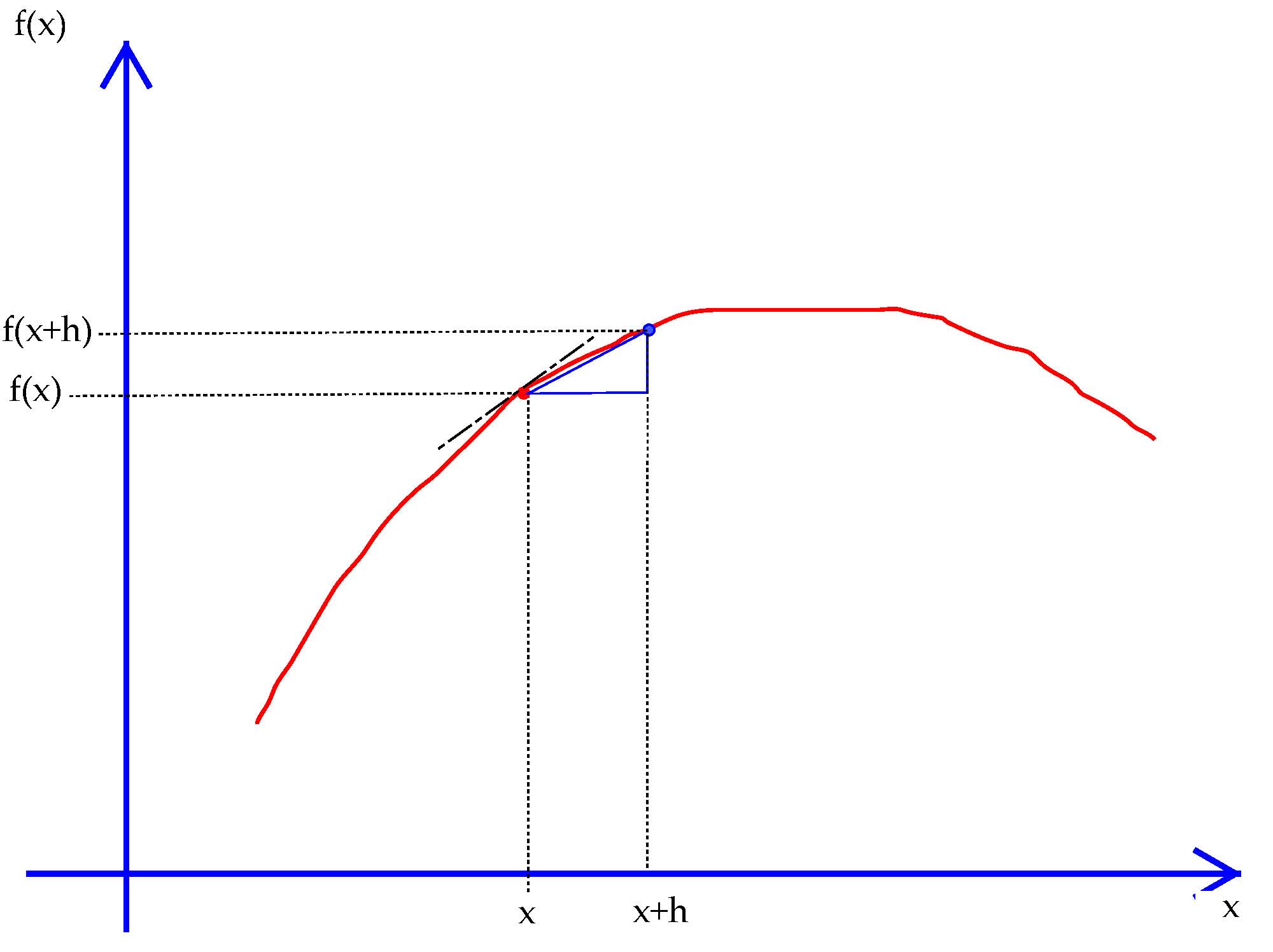
This is called a forward-step derivative: add a small (but not too small) number to $x$ and divide by that number.
Exhibit 33. Analytic versus forward-step numerical derivatives
The derivative of $f(x)$ at a point $x$ equals the slope of the tangent line. The forward-step numerical derivative is the slope of the secant line between $x+h$ and $x$.
On the other hand, the derivative could be defined as
$$f^{\,\prime}(x)\quad =\quad \lim_{h\to 0}\ {f(x+h/2)-f(x-h/2) \over h}.\tag{Cstep}\label{Cstep}$$
In the limit the difference between \eqref{Cstep} and from the usual definition goes away.
When $h$ is small (but not too small) there is a difference between a forward step and a central step. By keeping $f(x)$ inside rather than on one edge the finite approximation is almost always better:
$${f^{\,\prime}_{CD}(x) = {f(x+h/2)-f(x-h/2) \over h} \approx f^{\,\prime}(x) }\tag{CD}\label{CD}$$
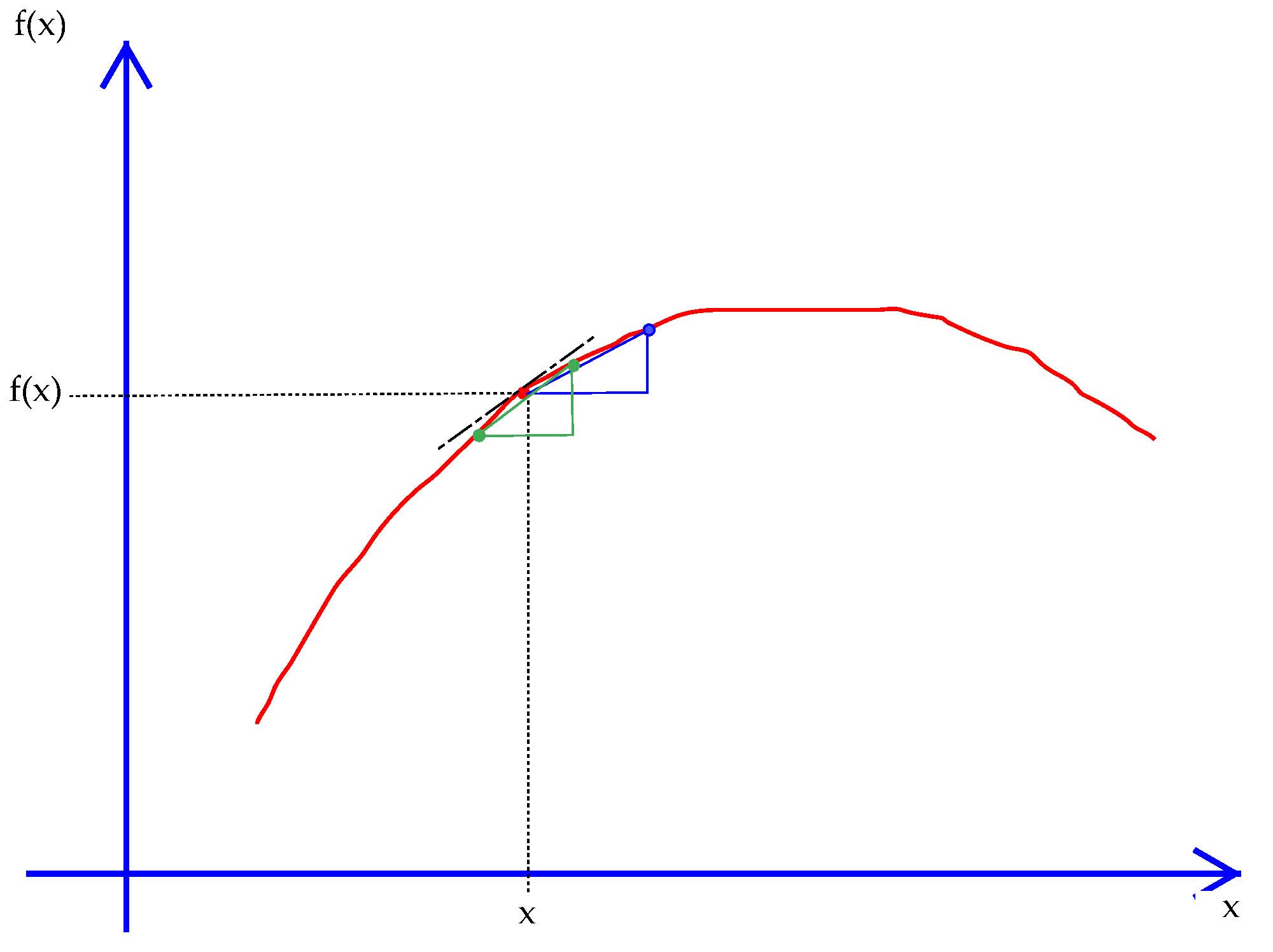
Exhibit 34. Central-step derivatives
The central-step numerical derivative is the slope of the secant line between $x+h$ and $x-h$.
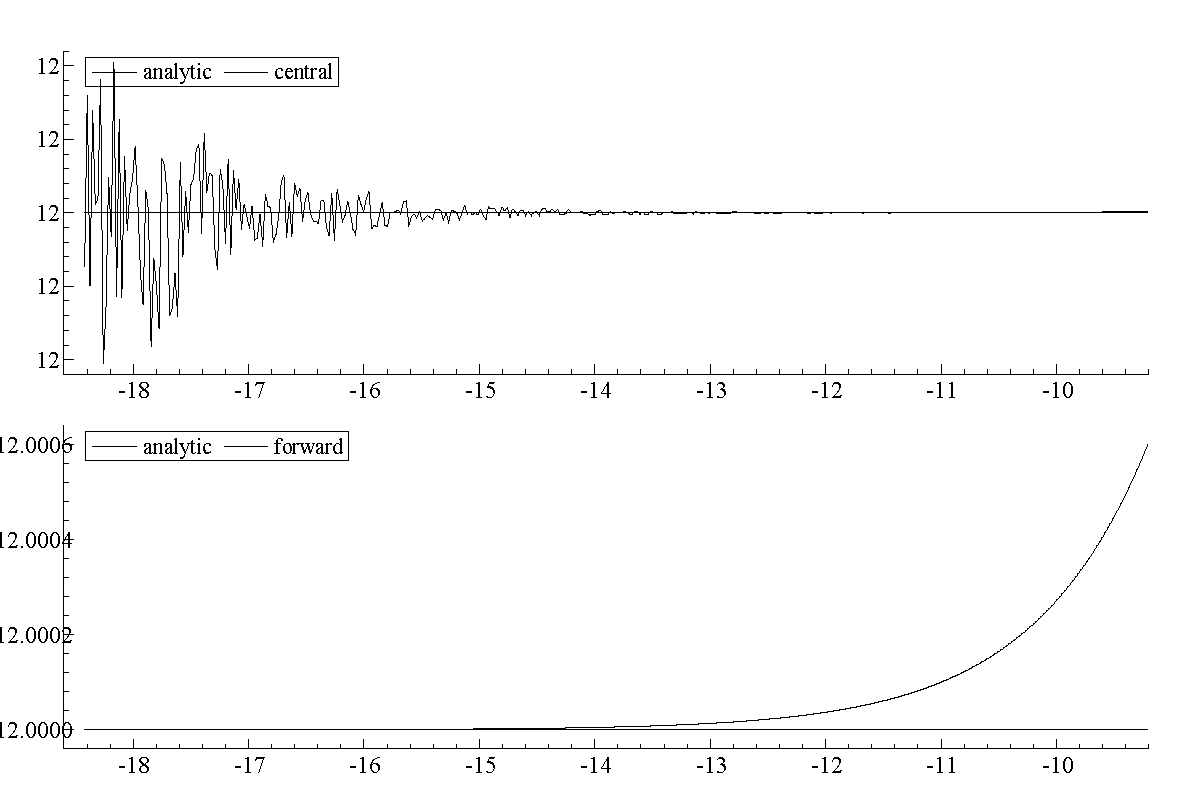
How much better? And how big should $h$ be? We can see what happens when we apply (CD) and (FD) to a function for which we know the analytic derivative. The program
Exhibit 35. Numerical Derivatives and the Value of $h$
Now consider taking the derivative at $x=1.0$ and $y=10000.0$. Should the same $h$ should be used for both? If so, round-off errors may become an issue. Adding $10^{-4}$ to $10^{4}$ has different implications for round-off error in FPRs than adding it to $10^{0}$. One way to adjust the step size is to make it proportional to $x$. That is, $h = \delta x$, where $\delta \approx 10^{-4}$. But this fails if $x=0$, since then $h=0$. Numerically we want to ensure that a minimum step size is maintained that does not flirt with machine precision.
Algorithm 7. Central-Difference Derivative with Safe Proportional Step Size
Set $h \approx 10^{-5}$, a standard step size for $x=1.0$.
Set $d \equiv (\epsilon_{m})^{1/2}$, a minimum step size well above machine precision.
Let $h_{x} = max( (|x|+d)*h , d )$, either a proportional or minimum step.
The algorithm above handles a single derivative, $f^{\,\prime}(x)$. The idea extends to multi-dimensional functions. The second derivative is the derivative of the first derivative:
$$f^{\,\prime\prime\,}(x) \equiv {d^2f(x)\over d x^2} = {d\left[{d f(x)\over dx}\right]\over dx} = \lim_{h\to 0}\ {f^{\,\prime}(x+h)-f^{\,\prime}(x)\over h}.\tag{2ndD}\label{2ndD}$$
Of course, if we have an analytic first derivative we could compute the second derivative numerically on it. But what about taking a numerical derivative of a numerical derivative?
First, inside (2ndD) substitute the definition of a numerical central-step derivative in for $f^{\,\prime}(x)$ using $h$ as the step size. Then approximate the second derivative with a central-step derivative on that, using the same $h$. The result simplifies into an expression that requires three evaluations of $f(x)$ not four, because two of the steps cancel out.
$$\eqalign{f^{\prime\prime}(x)\quad \approx &\quad { { f\left(x+h/2+h/2\right)-f\left(x-h/2+h/2\right)\over h} - { f\left(x-h/2+h/2\right)-f\left(x-h/2-h/2\right)\over h} \over h }\cr
&=\quad {f(x+2h) - 2f(x) + f(x-2h) \over h^2}\cr} \tag{F2CS}\label{F2CS}$$
Partial Derivatives: Gradients, Jacobians and Hessians
KC 7.4, 9.3
Before talking about partial derivatives and other aspects of multivariate calculus it may be helpful to talk about different ways to write down functions. An example would be a Cobb-Douglas function of two variables, which might be written
$$f(x,y) = x^\alpha x^\beta.\tag{CobbDougA}\label{CobbDougA}$$
Excluding $\alpha$ and $\beta$ from the list of arguments (and using Greek not Latin letters) emphasizes that $x$ and $y$ are variable and $\alpha$ and $\beta$ are fixed parameters. This form also emphasizes the difference between $x$ and $y$ which might help a reader focus on their differences. However, this notation gets very unwieldy if we want to think about 3 or 4 or dimensions or $n$ dimensions in general. For two dimensions we can start using the same letter and different subscripts:
$$f(x_0,x_1) = x_0^\alpha x_1^\beta.\tag{CobbDougB}\label{CobbDougB}$$
This is still the same function, just renaming $x$ to $x_0$ and $y$ to $x_1$. Notice that this form of the function treats $x_0$ and $x_1$ differently. We have to include the subscripts and then keep track of which exponent parameter ($\alpha$ or $\beta$) goes with which element of the vector. We can change it a bit so that the exponents also have exponents that match up with the arguments:
$$f(x_0,x_1) = x_0^{\alpha_0} x_1^{\alpha_1}.\tag{CobbDougC}\label{CobbDougC}$$
This is again the same function. We have just changed $\alpha$ to $\alpha_0$ and $\beta$ to $\alpha_1$. This form becomes unwieldy when we want to think about $n$ arguments instead of a firm 2 dimensional function. In this case we would have to write $x_0,x_1,\dots,x_{n-1}$ everywhere. Instead, we can first define an argument vector,
$$x = \l(\matrix{x_0\cr x_1\cr \vdots\cr x_{n-1}}\r).\nonumber$$
Some formulas and expressions depend on whether $x$ is defined as a row or column vector. These notes will assume a column vector because this matches with what built-in Ox functions will expect when we send them our own functions to process. We can reduce the notation a bit:
$$f(x) = x_0^{\alpha_0} x_1^{\alpha_1}\ \cdots\ x_{n-1}^{\alpha_{n-1}}.\tag{CobbDougD}\label{CobbDougD}$$
We would also want to define a parameter vector $\alpha = \l(\matrix{\alpha_0&\alpha_1&\cdots&\alpha_{n-1}}\r)$.
Notice that we still have to use $\dots$ and different subscripts. To avoid that we can now use the product operator:
$$f(x) = \prod_{i=0}^{n-1} x_i^{\alpha_i}.\tag{CobbDougE}\label{CobbDougE}$$
In some cases we might want to think about using different parameter vectors in this functional form, say $\alpha$ and a different vector $\beta$. At this point it could get confusing unless we write out the right-hand-side of Version E for each parameter vector. This can be avoided by including the parameter vector in the arguments but someone making it clear it is not the same as an ordinary argument. One way is to use ;:
$$f(\ x\ ;\ \alpha\ ) = \prod_{i=0}^{n-1} x_i^{\alpha_i}.\tag{CobbDougF}\label{CobbDougF}$$
Now two different Cobb-Douglas functions of $n$ variables can be written $f(x;\alpha)$ and $f(x;\beta)$.
In standard mathematical notation this is about as far as we could go in generalizing/streamlining the notation. That is because there is no operation that raises a vector to another vector. But in Ox and other matrix-oriented languages we have dot operators which act on individual elements of vectors.
$$f(\ x\ ;\ \alpha\ ) = \prod x\cdot\hat{}\alpha.\tag{CobbDougOX}\label{CobbDougOX}$$
To define the partial derivative of $f()$ with respect to $x_i$ we have to add/subtract a small amount to $x_i$. It is a bit cumbersome to write out $\l(\matrix{ x_0 & x_1 & \cdots & x_i + h & \cdots & x_n}\r)$ in defining partial derivatives. We can use vector additions to make it simpler. Let $\iota_i$ be a $n\times 1$ vector with zeros everywhere except a 1 in the i$^{th}$ position: $\iota = \l(\matrix{0&0&\cdots&1&0\cdots}\r)$.
Then
$${\partial f(x) \over \partial x_i} \equiv \lim_{h\to 0}\ {f\left(x+h\iota_i\right)-f\left(x\right)\over h}.\tag{Fpartial}\label{Fpartial}$$
The gradient is the vector made up of partial derivatives:
Other notation is kept consistent if we think of the gradient as a row vector not a column vector like $x$.
For computing the gradient $\nabla\,f$ with a forward step requires $n+1$ function evaluations. A central-step gradient requires $2n$ evaluations. So if computing $f$ is costly this can be a big difference, but typically the improvement in precision is worth it.
Each partial derivative of $f(x)$ has second derivatives with respect to each component of $x$. The resulting matrix of second partial derivatives is called the Hessian of $f(x)$
$$Hf(x) = \left[ {\partial^2 f(x) \over \partial x_i \partial x_j } \right] = \left[\matrix{
{\partial^2 f(x) \over \partial x_1^2}&{\partial^2 f(x) \over \partial x_1 \partial x_2}
&\cdots&{\partial^2 f(x) \over \partial x_1 \partial x_n}\cr%
{\partial^2 f(x) \over \partial x_2 \partial x_1} & {\partial^2 f(x) \over
\partial x_2^2}&\cdots&{\partial^2 f(x) \over \partial x_2 \partial x_n}\cr%
{\partial^2 f(x) \over \partial x_n\partial x_1}&{\partial^2 f(x) \over \partial x_n
\partial x_2} &\cdots&{\partial^2 f(x) \over \partial x_n^2 }\cr
}\right]$$
The definitions above all concern real-valued (scalar-valued) functions. The Jacobian expands the notion of gradient to vector-valued functions. Now let $f:\Re^n \to \Re^m$. As a vector-valued function $f$ can be written as a vector of component functions:
$$\mathop{f(x)}\limits_{_{m\times 1}} = \l(\matrix{ f_1(x)\cr f_2(x)\cr\vdots\cr f_m(x)}\r) = \left[\ f_i(x)\ \right].\tag{Vvfunc}\label{Vvfunc}$$
Each component function of $f(x)$ can have partial derivatives with respect to each element of $x$.
That is, $\partial f_i(x) / \partial x_j$ is the partial derivative of the $i^{th}$ component of the output vector with respect to the $j^{th}$ element of the input vector. In total there would be $nm$ such partial derivatives.
If we put all the partial derivatives in a matrix, then we call it the Jacobian of $f$:
$$Jf(x) = \left[ {\partial f_i(x) \over \partial x_j } \right]
=\left[\matrix{
{\partial f_1(x)\over\partial x_1}&{\partial f_1(x)\over\partial x_2}&\cdots&{\partial f_1(x)\over\partial x_n}\cr
{\partial f_2(x)\over\partial x_1}&{\partial f_2(x)\over\partial x_2}&\cdots&{\partial f_2(x)\over\partial x_n}\cr
\vdots&\vdots&\cdots&\vdots\cr
{\partial f_m(x)\over\partial x_1}&{\partial f_2(x)\over\partial x_2}&\cdots&{\partial f_m(x)\over\partial x_n}\cr
}\right].\tag{J}\label{J}$$
For $m=1$ the Jacobian is the gradient, $\nabla\, f(x)$. This is why defining the gradient as a row vector keeps the dimensions straight.
For a given real-valued $f$ and $x$, the Hessian is a square matrix. The Hessian matrix for $f(x)$ is a (very) special case of the Jacobian of a system of functions. In particular, the Hessian of a real function is the Jacobian of its (transposed) gradient:
$$Hf(x) = \left[ J\left[\nabla\,f\right]^T\right](x).\nonumber$$
Calculus in Ox
Here is material from the Ox documentation for the standard package maximize.
#import "maximize"
Num1Derivative(func, x, aGrad)
Num2Derivative(func, x, aHess)
Argument Explanation
------------------------------------------------------------------------------------
func a function computing the function value, optionally with derivatives
x p x 1 vector of function parameter values
aGrad address to place the gradient vector (as a p x 1 vector)
aHess address to place the p x p Hessian matrix
Return value
1 if successful
0 otherwise.
These functions carry out central-step derivatives for a user-defined function. In other words, you simply have to code $f(x)$ and these routines will compute the gradient or Hessian for real-valued functions. The argument func is the function to differentiate. To use these routines you have to write your function in the form they expect. If you don't do this they will not work. The documentation goes on to explain this:
The supplied func argument should have a format
#import "maximize"
func(x, af, ...);
Argument Explanation
------------------------------------------------------------------------------------
x p x 1 matrix with coefficients
af address to put f(x)
Returns
1: successful,
0: function evaluation failed
The argument … says that the function can take other arguments (see variable arguments in Ox). These other arguments are not needed or used when interacting with the numerical derivative routines. But when interacting with other built-in functions you might need to access values sent in the other argument places.
Consider this very simple function:
$$f(x_0,x_1) = -x_0^2 + x_0x_1 - x_1^2.\tag{Df}\label{Df}$$
According to the format above, a program to compute the numerical derivative of myfunc() would look something like:
To compute the Jacobian of a system (a vector-valued function), you use
#import "maximize"
NumJacobian(func, x, aJ);
Argument Explanation
------------------------------------------------------------------------------------
func a function returning the n x 1 non-linear system
x p x 1 vector of parameter values of the system
aJ address to place the n x p Jacobian matrix for the system
The supplied func argument should have the following format:
func(ag, x);
Argument Explanation
------------------------------------------------------------------------------------
ag address to place the n x 1 vector value of the system g(x)
x p x 1 vector of parameter values of the system
Returns
1: successful,
0: function evaluation failed
Exercises
Modify 24-fgrad-eps.ox to compute the derivative of $f(x)=\sin(x)$. Look up the analytic derivative if you do not remember it. Compare the numerical results to the analytic value at different values of $x$, including some near the top of $\sin(x)$ and some in between a peak and trough.
Write an Ox function f(x) which returns $f(x) = x^a$. Here $x$ is a variable sent to the function and $a$ is a parameter which is stored in a global constant. Use the dot exponent operator .^ so that if $x$ is a vector your function will return the vector of values.
Recall that $f^{\,\prime}(x) = ax^{a-1}$. Add a function fp(x) which returns the analytic derivative of $f(x)$. Set $a=3$ and have your main program call $f(x)$ and $fp(x)$. Print out the returned values for $x=2$ and confirm the values are correct.
Write a function to compute the general Cobb-Douglas form in (CobbDougOX) with these features:
Use return to return the resulting value of the function.
Use a static global constant to store $\alpha$.
Use .^ and prodc() to implement the symbolic operators in (CobbDougOX)
Your function can be written with one statement inside its curly brackets.
Write a program to compute the numerical first and second derivatives of
$$f(x_0,x_1) = \log\left({e^{x_0}\over 1+e^{x_0}}\right)+\log\left({1\over 1+e^{x_1}}\right)\nonumber$$