details tag ... details is not supported by Firefox or Explorer as of this writing.
niqlow/examples/GetStarted.ox niqlow/examples/GetStartedMain.oxTo run the program and see results:
oxl GetStartedMain
N-1everywhere is not elegant.
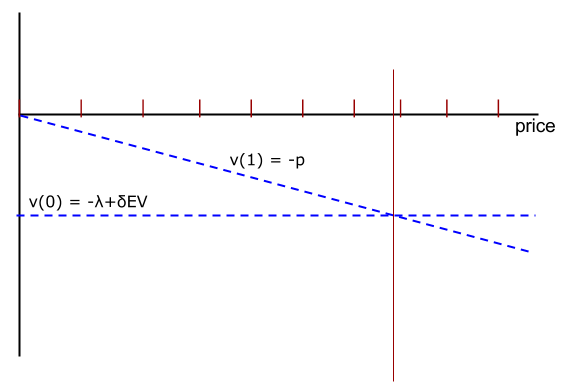
InfiniteHorzion. The action vector \(\alpha\) contains a single binary ActionVariable: \(\alpha = (a).\) The offer price is \(p\) is an instance (object) of the SimpleJump class.
LaggedAction class. d=1 is in the terminal set, \(\overline{\Theta}\).
Because price offers are IID it can be put into the exogenous state vector \(\epsilon\) contains one variable, ε = (p). Since the transition for \(d\) depends the current action it is placed in the endogenous state vector \(\theta\), which always contains a time variable as well: \(\theta = (d t)\).t=0.
Utility depends on current state variables, actions and parameters:
= -(1-d)*[ lam + a*p ]lam ≡ λ. Further, multiplication uses *. However, since p, a, and d are objects, the Ox code to implement \(U()\) will require more than just referring to the variable in the expression.
1: #import "DDP"
2: class Search : Bellman {
3: enum{Noff=10}
4: static const decl lam = 2.3;
5: static decl p, d, a;
6: static Build();
7: static Create();
8: static Run();
9: Utility();
}
.h or .oxh) file, but in the source code for this example it simply appears at the top of the .ox file.class (or struct). See OOP in Ox. The class name is Search. It is derived from an underlying class, Bellman. The code inside {} declares variables (data members) and functions (method members) that are needed to code the model. Each instanceof a
Search created while the program executes will represent one point in the state space. Aspects of the model that are shared across points in the state space are stored as static members of the class. Non-static elements are called automatic in Ox, but something is automatic by default unless the tag static appears when it is declared.
A with two static members and one automatic member. Then three new instances (objects) of class A are created using the new operator.
class A {
static decl a, b;
decl c;
}
d = new A();
e = new A();
f = new A();
There are now three versions of A.c in memory but still only two locations A.a and A.b.A
A::a
A::b d e f d.c e.c f.c
A::a ≡ d.a ≡ e.a ≡ f.a. A::b ≡ d.b ≡ e.b ≡ f.b. d.c !≡ e.c !≡ f.cHowever it is referenced,
a and b refer to the same place. On the other hand, each instance of A has a distinct c. So there are 5 distinct storage locations, two shared and three specific to the instance of A.method. DDP requires two methods. Method for the class of DP solution methods. (Upper and lower case do matter in Ox.) Unfortunately this may cause some confusion. An attempt in these notes will be made to use "solution method" for dynamic programming method and just "method" when using it to refer to a function that belongs to a class. Run() and Model() are not required, but they help organize the set up and solution of the model. In addition, they are organized to make it easy to build on the basic Search class without having to modify this code (see Get Started With Data).method Utility() cannot be static and must have the name and declaration Utility(). It returns the one-period payoff.
10: Search::Utility() {
11: return -(1-CV(d))*(lam + CV(p)*CV(a));
}
CV() function.
12: Search::Create() {
13: Initialize(new Search());
14: Build();
15: CreateSpaces();
}
16: Search::Build() {
17: SetClock(InfiniteHorizon);
18: SetDelta(0.99);
19: Actions(a = new ActionVariable("a",2));
20: EndogenousStates(d = new LaggedAction("d",a));
21: d->MakeTerminal(1);
22: ExogenousStates(p = new SimpleJump("p",Noff));
}
23: Search::Run() {
24: Create();
25: VISolve();
26: Delete();
}
Initialize() method before setting up the model.
Initializenew. So it is not possible to put these tasks in the constructorfor DP. The user may declare a
Initialize() method if they expect the class (Search) to be used as a base for other derived classes. Then Search::Initialize() would call DP::Initialize() and the prefix will be required to resolve the name.Initialize is an object of the model class. An example of the simplest way to do this is show above: new Search(). This creates an object of the user's model class, in the example Search. Initialize will clonethis object for each point in the state space of the model.
Initialize() and before the CreateSpaces() method is called. This code is contained in Build(). The code inside the Build function could be inserted at this point. However, following this pattern of defining a Create() and Build() function makes it easier to build on code to extend or change a model without copying or altering existing code.CreateSpaces() will create the action, state, and group spaces. This does not solve the model which is done after the creation step.InfiniteHorizon is an enumeration like Noff in the file above which SetClock() uses to create the right kind of clock. SetDelta() sets its value, which is constant here but could be set to a variable Parameter..integer as it might be coded in FORTRAN or C. By making it an object DDP can keep track of all the requirements of having a binary choice in the model without making the user do additional programming. When it is created, the user gives the action a label and says how many different values are feasible for the variable, in this case a.N=2. This happens inside the call to Actions(). DDP must know about the action variables in your model. It cannot peer into the Search class and see that a variable a is there and stores an action variable object. On the other side, action variables cannot insert themselves into your model. The routine Actions() adds the argument(s) sent to it to the model, putting them in the action vector \(\alpha\).
v=6 stores 6 in v and returns 6 as a result. print(v=6) will print 6. A subtle point that is further explained in other parts of the documentation is that Ox will return a reference to a. So what Actions() stores is a pointer to a not a clone or copy of it.StateVariable class. State variables require more information than action variables to be handled properly. In the model \(d\) tracks the choice made in the previous period. This kind of state variable appears in many models so a class for that kind of variable is predefined in DDP: the LaggedAction class. The action that d should track is sent as an argument when a new object of the class is created.
StateVariable. Indeed, d and a are fourth cousins, because states and actions are both derived from an underlying Discrete class.d=1 is a terminal state. DDP must know this so that the value of reaching that state is taken from its utility not iterated on using Bellman's equation. MakeTerminal() is a StateVariable method that can take either an integer or a vector of integer values as its argument. d->MakeTerminal(1) would not work if \(d\) had not be assigned a state variable in the previous line.p.N different values with equal probability. In DDP this is a SimpleJump state variable. Since its transition does not depend on the current state or actions, DDP can be told this an exogenous state variable, reducing memory and computations. Build() is complete we return to line 15. All elements have been created and added to the model, the user's code calls CreateSpaces(). CreateSpaces() uses all the information available about elements added to the model to create the state space, the feasible Action sets and many other aspects of the problem. To conserve memory requirements and computational time DDP does not create separate points for the exogenous elements of the state space (here \(p\)). It treats these separately and attachesvalues related to the exogenous states to the points in the endogenous state space, \(\Theta\).
MyModel. It also calls outAllV() so that a summary of the solution is printed to the screen. Solve() routine directly. One reason is efficiency. VISolve() creates and destroys the value iteration object each time it is called, which would waste computation if it were called repeated.Delete() re-initializes the model to be empty, with no variables or other features defined. This is only important for test code like this when another simple might be created after this one.Bellman or another class derived from Bellman. The user code must always call Initialize() for the parent class.CreateSpaces() to set up the state space and other aspects of the model. The user's code must define a function that returns a new instance of their class which is passed to CreateSpaces(), which will call that function for each point in the state space \(\Theta\).Utility method and a function. This replace the virtual method in Bellman of the same name.
GetStarted.ox does not run on its own. Like C, Ox needs to find a single routine called main() which is where execution of the program starts. Often main() is defined in a file on its own. To run the code from there the #include directive can be used to bring other code into the program.main() program file to run GetStarted:
main() does only one thing. It calls Run() which does all the work. Since Run() is static it can be called without referring to an instance of the class previously created with the new operator. There does not have to be an instance of the class for a static variable to exist. In general a user will only call static elements of their model. The DDP code will create instances of the class to represent states and process them internally.
niqlow/include is on the include path)
#include or #import then Ox needs to be able to find the code on the machine. Computer languages like Ox are designed to look in different places for code so that you do not have to copy everything to the same folder as your program. The list of places to look for things you include is called the include path. And Ox calls its list OX7Path, which is an system environmental variable (if that helps explain it). You can add a folder, such has \Users\Me\Oxpgms to OX7PATH when you run Ox by doing this:
oxl -i\Users\Me\Oxpgms myprog
If you use OxEdit or some other code editing program then you can set it up so folder(s) are added to the include path automatically so you do not have to type it each type. See Ox Pathoxl GetStartedMain
DP::Volume). When the spaces are created a summary of the state variables, state spaces, action vectors, and feasible action sets is produced. The Vprint() routine prints out information for each point in the endogenous state space \(\Theta\): The value of state variables in \(\theta\), \(EV(\theta)\), and choice probabilities averaging over the exogenous states. Since EV = -6.26 the searcher will accept any offer with a price below 6.26. There are 7 such offers, 0 through 6, and each is equally likely. So the probability that \(a=1\) is 7/10 or 0.7. The rejection probability is 0.3.Search model described at GetStarted.
MyModel class.h and .ox files, imported), and a new class is derived from the Search class.
struct DerivedSearch : Search {
static decl u, simdata;
static Create();
static Run();
}
DerivedSearch class adds members for data operations. The plan is to simulate behaviour of optimal search behaviour and to collect realized utility and indicators for price offers. Outcomes have space to store all realized actions and states, but utility or other functions of the outcome are not tracked automatically. The new code will track realized utility with an object stored in u. Simulated data are generated and stored as a OutcomeDataSet object, and simdata will be that object. The static Run() procedure will do the new work. All members of the base Search class are inherited and do not need to be declared or defined.
RealizedUtility. Here is the code for it, appearing in AuxiliaryValues.h and the source code AuxiliaryValues.ox:
Realize() function. code>Realize will be called only when simulating data (or in econometric estimation that involves matching predicted outcomes). Its first argument is the realized point in the state space \(\theta\)). The second is the current realized outcome \(Y\). This allows the auxiliary variable to access everything else.
Since AuxiliaryValue is derived from Quantity it has a current member, v. The job of Realize() is to set v for other aspects of the code to use. In this case, the auxiliary outcome calls Utility() and extracts the element of the vector returned that corresponds to the realized action. By using a virtual method Realize, the base DDP code can update your auxiliary variables for you without knowing ahead of time what those variables are. Also note that an auxiliary value can be sent to CV() after the call to Realize(). For example, here CV(u) will return the realized value of utility of the current outcome. So it is straightforward to build auxiliary variables into econometric objectives, equilibrium conditions, etc. (Besides Realize(), auxiliary values include a virtual Likelihood() method. This is called when computing LogLikelihood().
DerivedSearch relies on the base Build() routine discussed in GetStarted. All it has to do is create the auxiliary variable and then create a specialized data set object:
DerivedSearch::Create() {
Initialize(new DerivedSearch());
Search::Build();
u = new RealizedUtility();
AuxiliaryOutcomes(u);
CreateSpaces();
}
DerivedSearch::Run() {
Create();
VISolve();
simdata = new SearchData();
decl pd = new PanelPrediction();
pd->Predict(5,TRUE);
delete simdata, pd;
Delete;
}
struct SearchData : DataSet {
enum{N=15,MaxOb=20}
SearchData();
}
N and MaxOb will be used in SearchData(). Fifteen searchers will be simulated for up to 20 price draws.
SearchData::SearchData() {
OutcomeDataSet("SearchData");
Volume=LOUD;
Simulate(15,20,0,TRUE); //TRUE censors terminal states
Print(1);
ObservedWithLabel(Search::a,Search::p,Search::d);
println("Vector of likelihoods when offered price is observed:",exp(EconometricObjective()));
UnObserved(Search::p);
println("Vector of likelihoods when offered prices is unobserved:",exp(EconometricObjective()));
}
SearchData first calls its parent creator method.DataSet("Search Data",meth) where member meth was set by the parent Search. However, since Search::Run() is run first and it has already solved the DP model it would be redundant to solve it again.Simulate() generates the simulated sample by applying the conditional choice probabilities and transitions to initial states. N paths of the search model, each of maximum length MaxOb. Since the model has a terminal state, then any path may end before the maximum length. If there were not terminal conditions then the second argument determines how long each path really is. The third argument is a matrix of initial state vectors to use in the simulation. In this case a single state vector is sent. Since the model is stationary (t=0), and the non-absorbing state happens to be d=0, then sending a vector of zeros is appropriate for initial conditions. But in other situations this may not be the desired or well-defined initial state. d=1) is reached that outcome should not be included in the simulated path. The effect is to trim outcomes that are not needed. Once the agent has accepted a price the process is done. So the next state with d=1 is redundant for estimation purposes.DataSet class does not have a Simulate() method of its own.DataSet is derived from the Panel class the command simdata->Simulate(…) is equivalent to simdata->Panel::Simulate(…). This also means that the user could have made simdata a Panel object instead, if simulation was all that was required, but the data manipulation coming next require a DataSet object.Print(1) constructs a matrix representation of the data set and prints it to the output screen or log file.simdata can be printed out to see all this structure, but a great deal of output is produced which is not particularly helpful. Print() had been sent a file name with a valid extension then the simulated matrix would have been saved to a file (e.g. such as sim.dataor
search.xls).
Print() calls Flat() to flatten this data structure into a longmatrix, one row for each outcome and one column for each element of the full outcome Y* (except for the pointers to other outcomes). Columns for path id and simulated time are added.
Flat()is itself a recursive task that builds up the matrix by processing fixed panels, paths and outcomes recursively.force0 so that if reading in from external data the values will be filled in and they do not have to be explicitly observed. ObservedWithLabel() takes one or more action/state/auxiliary objects as arguments. L label of the object is the same as the label or name of the column in the data set, which is how the data is matched with the model variable.Y* in memory. Read(const filename). But here, observability is specified ex post. Volume is set to SILENT the masking method will print out a table summarizing the observability of the total outcome.exp() in this small example . As with all objectives in FiveO, it returns a vector of values that an algorithm will sum up or use directly to compute Jacobians as needed.Print(filename) and read into a new data set.) However, it is possible to undo observability, as the next line illustrates. In the first evaluation of the likelihood the offered price, p was treated as observed. Now, that mark is undone by sending the variable p to UnObserved() and re-masking the data. The next likelihood will integrate out the offered price.d. d=1 was censored from the simulated data all the observations have active searchers. However, Mask() does not know this so unless d is marked as unobserved. This creates a problem for rejected offer observations (a=0), because that is feasible when d=1. Thus, the built in log-likelihood will integrate over d=0 and d=1 when offers are rejected unless d is marked as observed. The user should remove d,UseLabel from the observed list and see the implications of this change.Source: ../../examples/output/Get_Started_with_data.txt
Search::Run() is called.path is an identifier for the realization, and since 10 were requested the ID goes from 0 to 9. Since the probability of accepting an offer is 0.7, most simulated paths will end after one period (t=0). Paths 2 and 7 include rejection of high prices in the first period followed by acceptances in the next period. Also, note that terminating states d=1 are excluded as requested.a, p, d as observed. Five aspects of the outcome are fixed (only take on the value 0), so force0 is equal to 1 for them. Since the data are simulated rather than external, each column index is -1. EconometricObjective is called the method is used and the model is again solved (in this case unnecessarily because nothing has changed).log(0) as -&infty;, and exp(-&infty;) as 0.p is undone and the objective is computed again.p from the observed list and re-masking the data. Now, with prices as treated as unobserved, the model is probabilistic. The model's chance that a=0 is the probability that realized p≥7, or 3/10. The chance of acceptance is 0.7, and for the 8 paths for which the first offer was accepted this is indeed the computed likelihood. This demonstrates that niqlow is able to account for unobservability of states (or actions) based on the model set up and the specified information about outcomes, which are treated independently of the model output and the full outcome Y*.T=10) to search over job offersz* at each t.policyiteration not
value functioniteration.
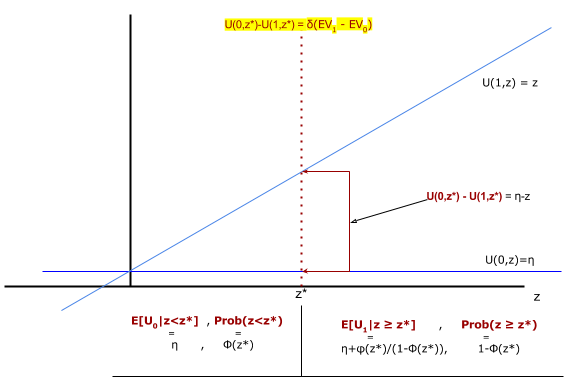
v(1,z*)-v(0,z*)=0
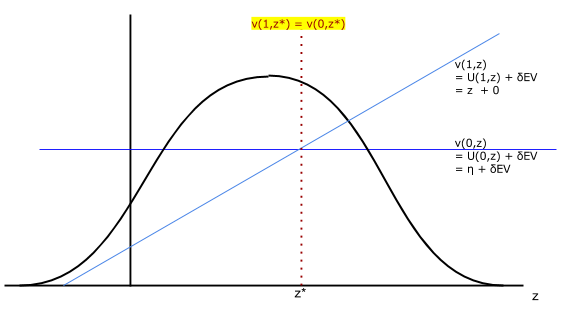
z*Uz(z). It returns a column vector with U(0,z*)|U(1,z*)|…. (More generally when there are N choices and N-1 cut-off values it should return a N × N-1 matrix.)a=0 given z*: \(E[U(0,z)|z\le z*]\). a=1 given z*: \(E[U(1,z)|z\gt z*]\).EUtility() which returns an array. The first element is a vector of expected utility differences. The second is a vector of probabilities.
Source: examples/misc/WStarA.h
Source: examples/misc/WStarA.ox
Source: examples/output/Finite_Horizon.txt
Source: examples/WstarTestb.pdf
/niqlow/examples/main.ox is an interactive program to run examples, test code, and replications. One of the options is to run GetStarted, GetStartedData and GetStartedRValues. To get started with optimization of non-linear objectives, see FiveO/GetStarted.