- The Same But Different Ox and C programs look alike and may appear to behave alike. For example, the same output is produced if
- Ox-C Lady
.six.ox six.c ---------------------------- ----------------------------------- #include <oxstd.h> #include <stdio.h>; main() { main() { decl h; int h; h = 6; h = 6; print("if ",h," was 9"); printf("if %i was 9",h); } } -------------------------------- Output ------------------------------- if 6 was 9 if 6 was 9 declinstead ofintprintinstead ofprintf.if
,h,was 9
if %i was 9
,h
This is not coincidence. Ox was designed to look like C. Also, both of these programs cause certain key things to happen. At some point during execution of either of them, a memory cell will contain 610 = - Compile, though your heart is breaking C is a compiled language, which means a C program is read as input by another program (the C compiler, such as
- From Code to Execution
- Lexical Analysis Using the program=food analogy, the first step is like chewing your food. The lexical analyzer part of the compiler takes the human readable text of the program and converts it to a list of the essential parts called a token list. The tokens include all the essential information from the program. Once the token list is created the source code is no longer necessary (although it might be kept to point to where the program goes wrong) A key part of lexical analysis is pre-processing.
#include <stdio.h>
tells the lexical analyzer to go find a file named - Syntax Analysis
- Compilation The C compiler now arrives at the task that earns it the name. The internally stored parse tree for the program is converted to a sequence of machine instructions to carry out the meaning of the program. The output of this stage of the process is called object code, as in the "the object of a compiler is to produce machine code". Unless we ask for another name, this sequence of instructions will be placed on disk in a file called
- Linking The linker is the part of the job that converts the object code into an executable file. That is, an executable file is one that can be loaded into RAM, put on the running program list and given control of the CPU. Among other things, the linker must make the connection between the identifer
- Running a Program in a Compiled Language To understand how programs go from code you write to binary instructions to run, it is necessary to think about when things happen. Here are some terms that will help keep things straight.
CodeTime: This is when the programmer is editing the source code, debugging errors from other times, coming up with test cases, input data, checking Facebook, etc.ParseTime: This is the source code going through pre-processing of source code, compiler directives, parsing text and creating the token list. Certain syntax errors are caught and reported at this time.CompileTime: During this time the object code (machine readable if compiled, pseudo-code if interpreted) is created. More subtle syntax errors are found (compiler errors).LinkTime: This is when creation of the executable file (if language is compiled) is created. Machine code for external functions referenced in the source code located; link errors are produced if code cannot be found or is incompatible with object file.LoadTime: The executable file (if compiled) or the interpreter is loaded into RAM and the entry point (first instruction) is put on the list of running programs; the Runtime environment is started to support execution.RT0: This is just when the program starts to execute, right before the first instruction is loaded into the machine's or interpreter's program counter (the MPC). Errors associated with memory, incompatibility, etc. can be caught at this point.RunTime: Machine code executes or interpreter executes pseudo object code. Output produced; Runtime errors are encountered including bad operands, file errors, numerical exceptions, out-of-memory, dynamic type incompatibility, etc. Output errors: results are not what is expected.
Ox is not compiled. It is an interpreted language, which is illustrated below.
x = 0.25; println( "Is 2.5=10*(0.25)? ", 2.5== x+x+x+x+x+x+x+x+x+x ? "Yes" : "No");
- Living in the Virtual World: programming in a compiled language not required Interpreted languages have existed for decades, but originally they were specialized and tied closely to the machine running the interpreter. Many older economists and their hipster colleagues have a strong aversion to interpreted languages because they were restrictive and slowed by the interpreter overhead. But in many domains the distinction is much less important than before, say, Java arrived. Java is an interpreted language, but it is designed as a general purpose language to run on all platforms, including devices that are not general purpose computers. The interpreter of the language is known as the Java Virtual Machine. Java programs can be compiled to pseudo-object code and then interpreted. The object code can also be compiled to a machine executable file.
- what created
gcc.exe - and
- what created
oxl.exe? - An example
decl I2 = unit(2); println("I inverse= ", invert(I2) );
That snippet of code in Ox would require dozens of lines of code in C to write from scratch. C does not know what a matrix is, so the do-it-yourselfer would have to include lines of code to return a $n \times n$ identify matrix. The C language itself has no matrix inversion code. On the other hand, Ox knows what a matrix is, even though it is a C program, and it has routine to create a I so the programmer can use it for economics. The code to invert a square matrix takes dozens of lines of C code, but in Ox it is a function ready to work for you.
V = B' * A * B;
A C math library, on the other hand, might translate the expression into something like
V = matmult(matmult(transpose(B),A),B);
six.ox is run in Ox and six.c is run as a C program
There are only three differences between the two files:
0000 ··· 01102. And the contents will be retrieved and sent to a segment of machine instructions that communicates with the screen or disk file to produce the character "6" for you to see.
Yet, at the machine level everything will be completely different between executing the C and Ox versions of six. This is because they are on different sides of the compiled / interpreted divide. (What I call interpreted
is also called scripted
.) In a compiled language, source code is ultimately converted to machine instructions (compiled). The executable instructions are stored in an executable file.
In an interpreted language your source code is never converted to machine instructions. The source code is an input (a script) to an interpreter, which is a program (itself interpreted or compiled) that runs the code. This distinction is less important than in the past, but can still be very important for writing good programs that are efficient. Understanding the implication of the difference will help you to avoid writing Ox programs that run slowly like molasses.
gcc). The C compiler eventually creates an executable file of binary machine code. Running the program means loading the executable file into memory and setting the computer's Machine Program Counter (MPC) to the first instruction in the code.
Compilation is to a program as digestion is to a meal. In digestion, food is taken in and broken down step-by-step until it can be used by the body for energy and nutrients. We will describe the process by which the C program six.c is converted to machine instructions that can produce output and do any other work a machine is capable of.
Since C is a compiled language, there has to be a program available to do the compiling. One C compiler is known as gcc. If we are compiling on a Windows machine, then the compiler would be a program on disk with the .exe extension. To do the work of compiling the program has to be RAM and be running as described earlier. So in the diagram below, the file gcc.exe has already been loaded into RAM and has been told to compile six.c.
Exhibit 19. From Program to Executable in a Compiled Language
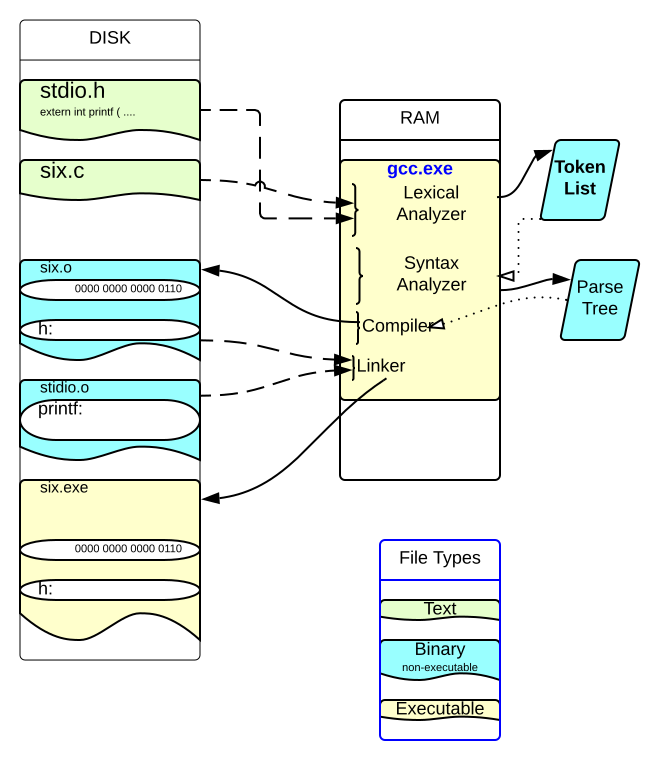
Pre-processing commands in C and Ox are indicated by #. The expression
stdio.h and insert its contents at the include as if they had been cut-and-pasted into six.c by the programmer.
This makes it much easier for the programmer to avoid duplication across different programs. The C compiler will know where to find stdio.h. Its name stdio means "standard input and output".
If you #include files not directly related to the C language the lexical analyzer may have trouble locating the file, causing a CompileTime error. If you do find stdio.h and search it for "printf", you will notice a few things. First, it is a plain text file that you can read. And, second, all it does is list printf () followed by some text and ending in }. In other words, the header file only declares that a function called printf() exists and could be used by the programmer if they want. It does not define what the function does, either as C code or as binary machine instructions. Apparently that happens somewhere else, but the compiler does not need those details in order to compile your program. It just needs to know that eventually the code for printf() will be available.
The token list strips the code down to its essential parts. For example, the token list would include the kind of token and its value: "main", "int", "h", and "printf" would each produce a token of type identifier. Meanwhile, "(", ")", "=", and some other bits would be symbol tokens. ' "if " ' converts to a literal string, and "6" would convert to a literal integer. Spaces and new lines between tokens and comments can play a role in separating tokens, so that "int h" is two tokens instead of one token, "inth". However, it does not matter if they are separated by one space or 50. Once the lexical analyzer has come up with the list of tokens other aspects of the original text file are thrown out and play no further role in the meaning of the C program.
Text editors can highlight the text of the program to make it easier to read and correct. The editor is constantly scanning the text and changing the font according to the rules of the language. But an editor that knows the syntax of a language is not a compiler. Instead, it is a "light" version of a lexical analyzer for the language. A compiler understands the rules of the language and can convert the intent of the program into machine instructions.
With the token list created, the compiler can now start to figure out what you want the computer to do. First, the C language has a syntax. A C program may not make sense because some kinds of tokens cannot follow other kinds. The sentence Food dog eat
does not make sense in English, so English does not allow the writer to put two nouns (food and dog) in a row followed by a verb (eat). In the same way, main h () { could not be the second line of six.c. You cannot just put two identifier tokens next to each other in proper C.
Note that just as human languages, the syntax can be okay but the meaning is not. Example, a native speaker of some languages might say in English, "Eat dog food" meaning that (a) dog eat(s) food. But in English the subject (dog) comes before the verb (eat). On other hand, this sentence is syntactically correct if it is a command to "Eat dog food!". Now the token dog is not the subject but an adjective modifying food. And in commands the verb comes first and the subject (you) is implied. So the syntax was acceptable but the meaning was not what was intended by the speaker.
In computer languages the syntax can be correct but the program fails to tell the computer to do what the programmer wishes. This kind of error can only be caught later on. At this stage only syntax errors like main h () are caught. The syntax analyzer produces a complicated object called a parse tree. This tree must convert the tokens into something that means something. For example, the parse tree will ensure that the tokens "h" that appear on lines 3, 4 and 5 all refer to the same thing. Every identifier has to match up with something. One identifier that is mentioned but not defined is printf(). If you looked at stdio.h you would find that it is mentioned there, but what printf() does is not. In C (and in Ox) header files do not typically include executable code, just the names of things for which the code is available somewhere.
six.o The object code may only exist temporarily or it may stay on the disk to be used later.
The diagram emphasizes that the object code is not understandable to humans. It is full of binary instructions specific to the computer doing the compilation. However, the semantics of the original program mean we know a few things about the contents of the object code. First, somewhere in the code is a memory location that will, during execution, hold the contents of the variable h. And since the literal number 6 is assigned to something in the code, this literal constant must be converted to a binary code for 6 and stored somewhere. So somewhere in six.o is a memory cell with a binary representation of six. Note that the contents of the location labeled h are left blank. That is because the object code does not do the work of the program, so the contents may be set to something or may be whatever pattern of bits happen to be on the disk.
Since our six program uses a built-in function called printf(), and since stdio.h does not define what the function does, the object file now has to do something about this. So it must look for the binary instructions for printf() and insert them into six.o, or set up six.o to go and get the binary code for printf() when it is needed. It turns out that it is the latter.
The binary instructions to print things out to the screen or a file in C are not included in the object file six.o. In fact, many bits of instructions that are required for the program to run are not present in the object file. In this sense an object file is not executable. It contains machine instructions but not all necessary machine instructions. By analogy to term papers, the object file can be seen as the main body of the text but not the list of references, table of contents, title page, etc.
printf() and the binary code for that function that is sitting in a file. The name of the file is probably not stdio.o. You may have some difficulty tracking down exactly where the object code for printf() is located, but that's because of issues that go beyond what we need. For our purposes let's just suppose that a file called stdio.o has the binary object code for each of the functions defined in stdio.h. Then it is the linker that will grab that code and link it to your code, ensuring that six.exe will use it when it is running.
Exhibit 20. From Program to Executable in an Interpreted Language
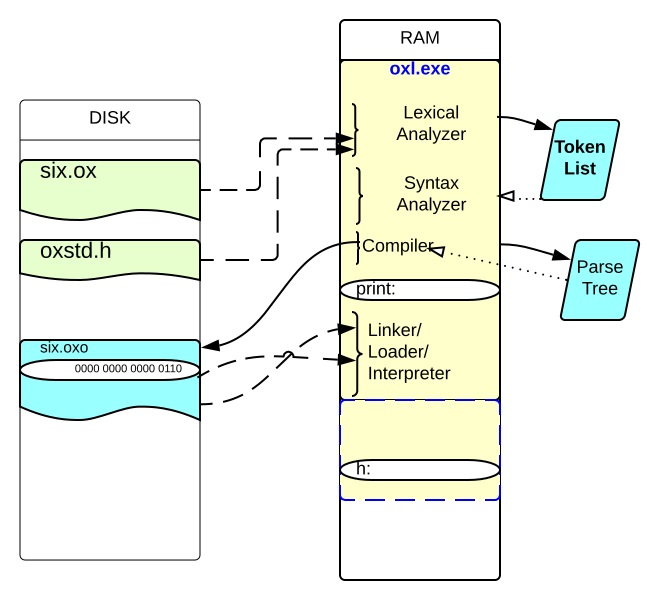
Converting six.ox into output starts out just like six.c. The program's text is parsed into tokens and then a parse tree by another running program, oxl.exe. This leads to an object file, with extension .oxo (Ox object file). But the object file in an interpreted language does not consist of machine instructions. It contains instructions for the interpreter, not the machine. The interpreter is another program that is written to carry out the instructions implied by the program. The interpreter for Ox is also oxl.exe, and six.oxo is input that program. In a compiled language the user's executable file takes control of the machine to do the work. In an interpreted language, the user is never in charge of the machine.
Now consider what happens to 6 and h in six.ox. First, the constant has to stored somewhere in the object file so that the interpreting part of oxl.exe has it ready to assign to h. But there is no location in the object that will contain the contents of h. The object file is loaded into memory when running, but not as machine instructions, simply input for the interpreter.
The instructions that retrieve the contents of h are in oxl.exe not linked and loaded along with a file called six.exe. However, there must be some memory location for h, and there is. But it cannot be inside oxl.exe, because at the time it was compiled and linked six.ox did not exist. And the Ox interpreter inside oxl.exe could not be prepared to store every conceivable variable. In fact, oxl.exe was created on a completely different machine than the one running it now.
So oxl must use more memory than it started with in order to execute the commands intended by six.ox. If it simply used the next location after the end of oxl.exe, it will likely be corrupting the data or instructions of some other running program or the operating system itself. Computer systems do not let programs do this. They protect the locations under the control of other programs while a program is in control of the CPU during its slice of the timeshare arrangement discussed earlier.
Part of this control is the run time system (RTS), which assists running programs. Of course, the run time system does not operate simultaneously, since a single CPU can only perform one instruction at a time. Instead, some tasks in a language will implicitly request the RTS the next time it is in charge of the CPU. The running program, here oxl.exe, then waits until the task is done before going on with its work. (It "waits" by turning the CPU over to the OS and every time its slice of time starts it checks whether the RTS has finished. If not it continues to wait.
Thus, to execute six.ox the Ox interpreter inside oxl.exe gets a little more memory to store six.oxo. And then as it is interpreting the instructions in it, a little more memory is allocated to store h. This is illustrated in the Figure as showing the object file and the variable location in memory but beyond the bounds of oxl.exe. Where they end up in memory is up to the RTS and the OS. Return to a segment of the second program presented, 08-If6was9.ox:
Note that the constants 0.2510 and 2.510 must be converted to binary representations and then stored in the .oxo "file". (The word file is quoted because the Ox object code may never become a file on disk; it may only exist in RAM while oxl.exe compiles and then interprets the program.) Then the pseudo-code to repeatedly add the contents of x appears in six.oxo, and at run time the Ox interpreter will execute that code.
In many ways Java and later languages such as Python have blurred the distinction between compiled and interpreted languages. However, within the context of intensive computation, such as a solving and estimating a large scale econometric model, the distinction still matters. The overhead can destroy your performance, unless you are careful. Thus, it is still a common belief that real programmers use FORTRAN or C, in part because only compiled languages intrinsically efficient.
We have compared two kinds of languages, compiled and interpreted, and nearly identical programs written in each type (C and Ox). We have left two questions unanswered:
The answer is that a compiler created them both. The Ox parser/compiler/interpreter is itself a C program. So Ox is both a language, which has a grammar, and a C program that implements the language. Any work you do in Ox is really happening inside a C program. Despite the name, the interpreter for a computer language is more like a translator of human languages rather than an interpreter.
A translator takes statements in one languages and converts them to another. But it is free to revise the translation as it analyzes the source. An interpreter must translate in real time. A language that is like a human language interpreter is called interactive. Interactive execution is simply a case where each statement is parsed and executed before the next one in the source. Interactive programs can 'wait' for input to come in whenever the user (human or otherwise) is ready to give it. Ox can run in interactive mode. The interpreter is a different executable called oxli.exe but it is only available on Unix or with the professional version.
What is the point of writing programs that are merely input to a C program? Why not simply program in C? Do programs like Ox (or Matlab or R) exist only for people who aren't smart enough to write their own programs in C or FORTRAN? Do real economists only use FORTRAN?
Some people hold this opinion, but this begs the question, why use FORTRAN? Why not program directly in assembly language, which is just a step up from coding machine instructions directly? The answer: using C/FORTRAN will save a programmer a great deal of coding time because of the many details they see to that are unimportant for your task. But the same is true with compiled languages compared to languages written in them. Languages like Ox free the programmer from dealing directly with many issues that are not important to the task at hand but must be addressed by someone at some point.
Users of C would typically not do what I just said. They would not program from scratch the concept of a matrix along with the operators and functions such as matrix inverse. They would typically rely on a library of C routines for doing math, trusting that the writer of the library did a good job. In one sense you can think of Ox as a math library. (In fact, later on we show how a C programmer could use Ox functions as a math library.) But it is more than that because, as a language, an Ox programmer can translate the math $V = B'AB$ into the code
Use of a mathematical interpreted language like Ox (or Matlab or R) is convenient and reliable for math, but this comes with a price. If a C programmer relied on a math library, their code might not look as nice but the library functions are machine code that execute directly. In Ox the interpreter must be running while executing your more elegant Ox code. This creates an overhead cost of using an interpreted language instead of compiled libraries.
Some would say that programs/languages like C or FORTRAN are inherently faster than ones like Ox or Matlab. Later we explore this idea in detail. It is true that naive Ox code can be extremely slow compared to C code that looks very similar. But often the naive Ox code is less elegant than better code that runs much faster, even as fast as the C version. And the overhead cost can be as low as 0 compared to native C code, and RunTime overhead does not account for the CodeTime overhead created by using code that is farther from the mathematical statement of the problem.
Summary
- Computer languages are either compiled (ultimately creates machine instructions) or interpreted (run by another program); some interpreted languages are interactive.
- Both kinds of languages go through the same stages of digestion, but the nature of the object files are quite different.
- Executable files for a compiled language contain machine code for the program and code segments referred to by the program and stored in library files.
- Programs can ask for and receive more memory as they are running. This is dynamic memory allocation, and it can only work because the operating system provides real-time support for executing programs, called the run time system.
- Interpreted languages include overhead because the instructions are not executed directly by the CPU, but rather by another running program, the interpreter. Some tasks take much longer to do in an interpreted language than in an interpreted language. But not all tasks take longer, and in some cases an interpreted language can execute a task faster than a compiled language.